
Ретушь кожи методом частотного разложения
Видео: Ретушь кожи методом частотного разложения
При обработке портрета часто возникает вопрос о том, как сохранить текстуру кожи, избавившись от всех неровностей и изъянов. Существует фильтр для Фотошопа Portraiture, который делает кожу пластиковой. Это не правильно. Сколько бы ни говорилось о том, что использовать его нужно умеренно, и дозировано, результат его применения оставляет желать лучшего. Мы сейчас поговорим о том, как достигнуть хорошего результата. Это способ не для ленивых.
Частотное разложение — это метод ретуши, который известен уже давно. Он сложен в освоении, но в дальнейшем его достаточно легко применять на практике. Все действия по разложению можно записать в экшен, и тогда процесс обработки максимально автоматизируется и упрощается. Данная статья пошагово опишет весь процесс разложения по слоям.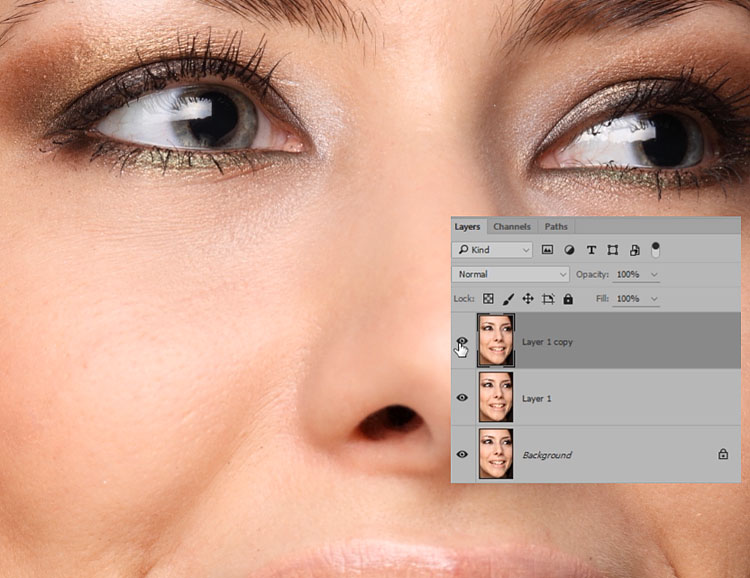
На фотографиях уже убраны все прыщики и некоторые изъяны кожи инструментами Healing Brush Tool и Path Tool. Лишние пятна убираются прорисовкой светотеневого рисунка. Изображение после первоначальной коррекции стало немного лучше, но с фактурой кожи еще нужно поработать.
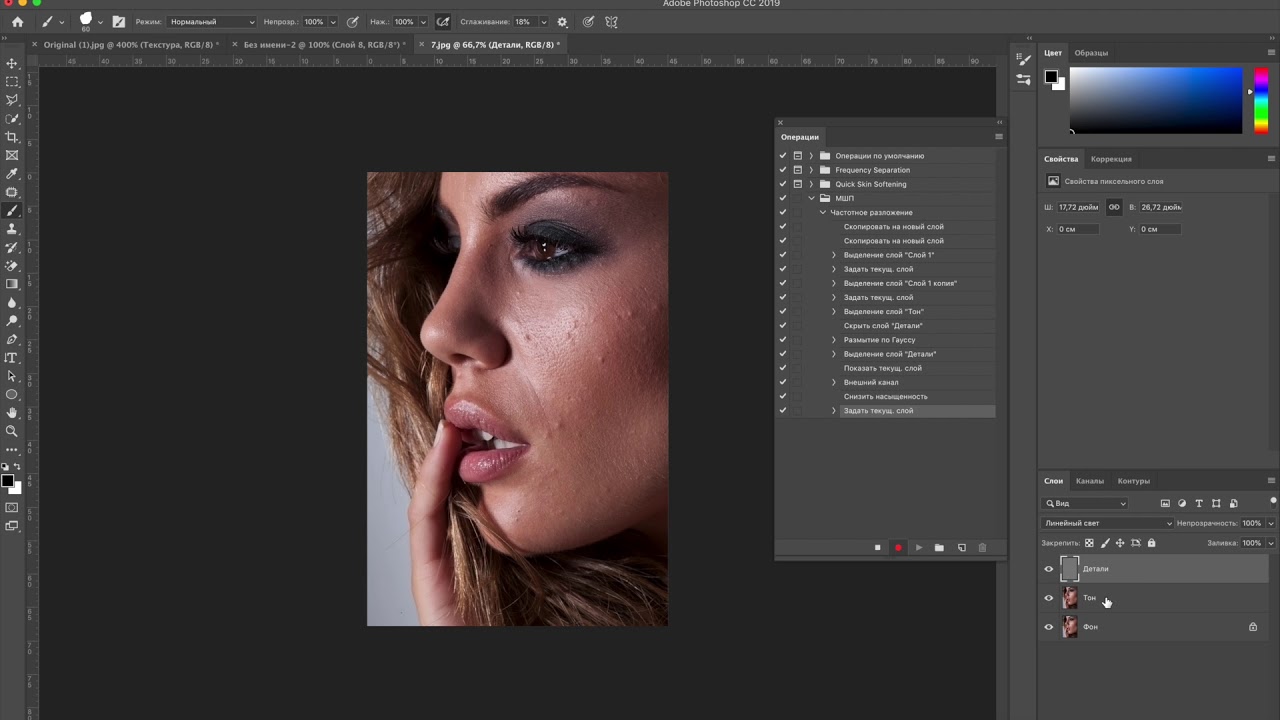
Приступим. Создаем копию фона и отправляемся в меню Filter-Other-High Pass. Под действием фильтра слой становится серым. Настройки устанавливаем на значение 6 рх. Значение можно изменять в диапазоне 2 — 11 рх. Выбор настроек зависит от того. насколько фактура кожи крупная. При съемке потерта крупным планом, значение нужно устанавливать от 9 до 11 px. Если модель сфотографирована по пояс или во весь рост, то на снимке фактура кожи будет мелкой. В таком случае нужно устанавливать значение 2-4 рх. В данном методе очень важно правильно выбрать значение фильтра. Слишком маленькое значение не передаст фактуру кожи должным образом, а слишком большое — сделает её грубой.
Определившись с настройками, нажимаем Ок и переименовываем слой в High Pass.
Теперь меняем режим наложения всей группы на Linear light.
Картинка сразу стала цветной, но детализация слишком высокая. Сейчас займемся исправлением этого.
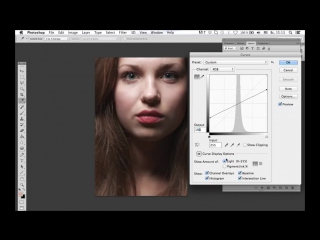
Мышкой выделяем слой High Pass, который находится в группе, и над ним создаем корректирующий слой Curves.
В настройках уменьшаем крутизну кривой как на скриншоте. Теперь можно закрыть это окошко.
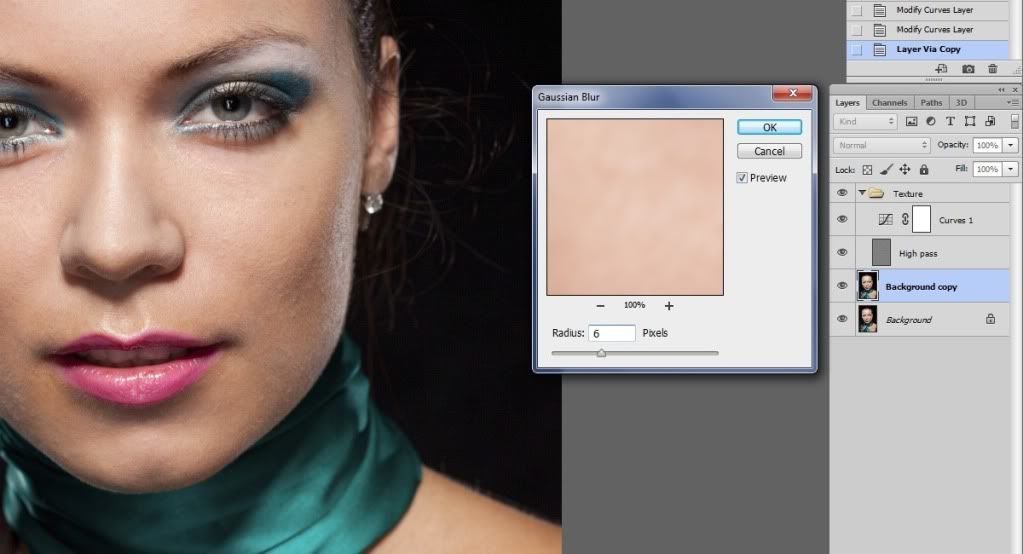
Теперь делаем копию фонового слоя еще раз. Применяем к нему Filter-Blur-Gaussian Blur и в настройках устанавливаем значение 6 рх. Очень важно то, что значения в применяемом ранее фильтре High Pass и в Gaussian Blur настройки радиуса должны совпадать. Применяем фильтр и изменяем название слоя на «Blur».
Этот слой тоже помещаем в новую группу, которую назовем «Spot»(пятна).
Теперь видно, что картинка приобрела изначальный вид. Если отключить все созданные слои, то видно, что никакой разницы нет. (Слои можно быстро отключить, зажав Alt+ клик по глазику. Это действие отключит все слои, которые находятся выше.) Смысл всех этих манипуляций в том, что в верхней группе у нас получилась текстура изображения, а в нижней группе можно рисовать, размывать и корректировать основу. Все действия в нижней группе не затронут текстуру.
Теперь, для того, чтобы нас не отвлекала текстура, отключим её. Перейдем в нижнюю группу. Мы видим пятна и неровности. Создаем копию слоя Blur и применяем Gaussian Blur. В этот раз размытие определяем на глаз. Размываем до тех пор, пока не исчезнут мелкие и средние пятна. Крупные пятна размером с нос или глас пока не трогаем. Размытие чаще всего выполняется со значением от 10 до 25 px.
Создаем для этого слоя маску и заливаем её черным цветом.
Белой кистью прорисовываем лицо, не трогая глаза, губы, ноздри и прочие контрастные участки.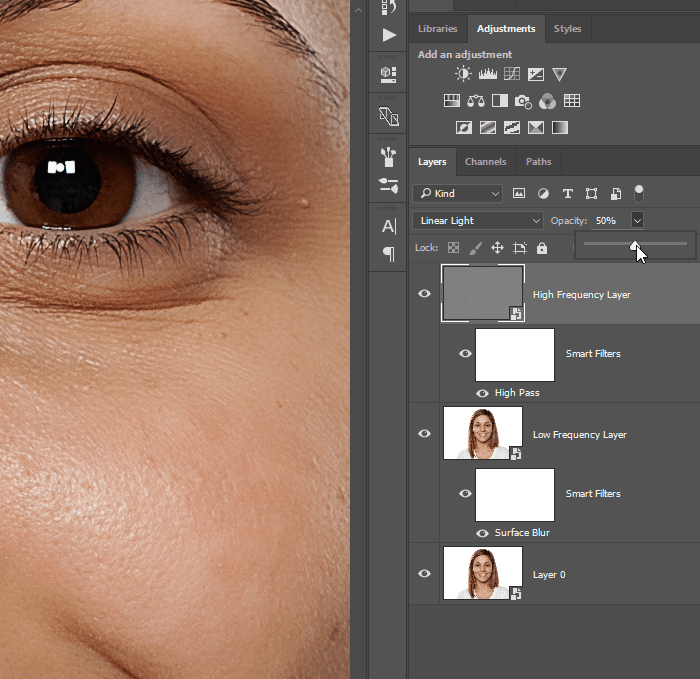 Чем больше будет применено размытие, тем дальше нужно держаться от границ, контрастных цветов. В противном случае они поплывут.
Чем больше будет применено размытие, тем дальше нужно держаться от границ, контрастных цветов. В противном случае они поплывут.
Далее над слоем Blur copy нужно создать новый пустой слой. Им мы будем убирать крупные пятна и блики.
Выбираем кисть и устанавливаем параметры Opasity и Flow равными 10%. Желательно, чтобы эти параметры были равны, так как при этом кисть работает более корректно. Пипеткой берем образец цвета из участка, который больше всего нравится. Кистью закрашиваем пятно в участке, которые не нравится. Этим приёмом можно убирать блики от вспышки или круги под глазами. При рисовании очень важно следить за ем. чтобы участки, которые подвергаются зарисовке не стали плоскими. Для качественной ретуши стоит иметь хоть какое-то художественное образование. Также не помешает походить на курсы визажистов.
Прорисовав все проблемные участки в группе » Spot «, мы переходим к работе в группе «Texture».
При всём пи этом отчетливо видно, что текстура в местах бывшего блика от вспышки и там, где были круги под глазами, стала слишком грубой.
Создаем копию слоя High Pass и берем Healing Brush Tool. В настройках кисти лучше сделать её овальной. Это позволит сделать воздействие кисти не таким заметным. Жесткость кисти ставим около 90%. В настройках кисти ОБЯЗАТЕЛЬНО нужно поставить Current Layer. Далее работаем кистью в обычном режиме. При помощи Alt берем нормальный участок и прорабатываем «больной». Если после работы кистью границы остались слишком резкими, то нужно наложить белую маску, и черной кистью с небольшой прозрачностью подтереть нужные места.
Если есть места со слабовыраженной текстурой, то нужно зайти на корректирующий слой Curves 1 и на маске слоя черной кистью с Opasity и Flow равными 20% прорисовать места со слабой текстурой. Текстура кожи в этих местах будет усилена.
Текстура кожи в этих местах будет усилена.
В конце обработки нужно уменьшить прозрачность слоя «Blur copy» до 70 — 80%. Значение 100% делает кожу слишком совершенной. Такого не бывает.
В статье описан только один этап обработки портрета. На снимках ниже показаны четыре варианта обработки: 1 — конвертация из RAW без изменений; 2 — следствие первичной обработки в RAW-конверторе, и прорисовки светотени; 3 — результат частотного разложения; 4 — финальный результат с проработкой цвета и контраста.
Посмотрим еще на несколько портретов, которые были обработаны методом частотного разложения.
На основе материалов с сайта: tolstnev.livejournal.com
Первичная чистка и частотное разложение
Исходная фотографияПривет! Меня зовут Саша, я один из основателей платформы для творческих людей “ТВОРЧmachine”.
Мы записали цикл бесплатных видеоуроков по естественной обработке портретов, который состоит из трёх частей:
- Первичная чистка и частотное разложение.

- Dodge and Burn, ретушь глаз.
- Глобальный контраст и добавление объёма в кожу, подготовка к публикации во ВКонтакте.

В первом 7-минутном видеоуроке из цикла я рассказываю, как на фотографиях избавляюсь от временных проблемных зон на коже базовыми инструментами Adobe Photoshop, а также демонстрирую один из вариантов механики ретуши под названием “Частотное разложение”.
Частотное разложение в фотографии — это приём, используемый фотографами и ретушёрами, основанный на разложении частот (в классическом варианте на низкую, среднюю и высокую). В низкой находится основное распределение цвета и яркости, в средней — объёмы объектов, а в высокой — мелкая детализация.
В нашем примере мы используем упрощённый вариант — деление только на “низы” и “верха”.
Исходная фотографияНачинаем ретушь с дублирования основного слоя (Ctrl+J для Win, cmd+J для Mac). Анализируя временные проблемные зоны (которые не преследуют человека всю жизнь: прыщики, болячки и синяки, неуложенные волосы и др. ), выбираем подходящий инструмент для лучшего результата. Я использую в большинстве случаев два:
), выбираем подходящий инструмент для лучшего результата. Я использую в большинстве случаев два:
- Patch Tool (Заплатка) — универсальный вариант для работы с кожей, позволяет практически бесследно убирать изъяны разных размеров.
- Healing Brush Tool (Лечащая кисть) — хорошо работает с волосами.
Следующий этап: разложить изображение на две частоты: верхнюю и нижнюю. Нижняя — общее распределение яркости и цвета, верхняя — вся текстура и детализация. Создаём две копии получившего слоя после первичной чистки. Один из них для удобства назовём Low, другой — High.
К слою Low, на который мы выносим яркость и цвет, применяем Filter—Noise—Median.
Значение радиуса зависит от конкретного случая. Алгоритм выбора: необходимо размыть фотографию настолько, чтобы переходы между светом и тенью были различимы, но плавны. В нашем случае это значение равно 15.
Переходим на слой High. Чтобы вынести на него текстуру, идём по пути Image—Apply Image.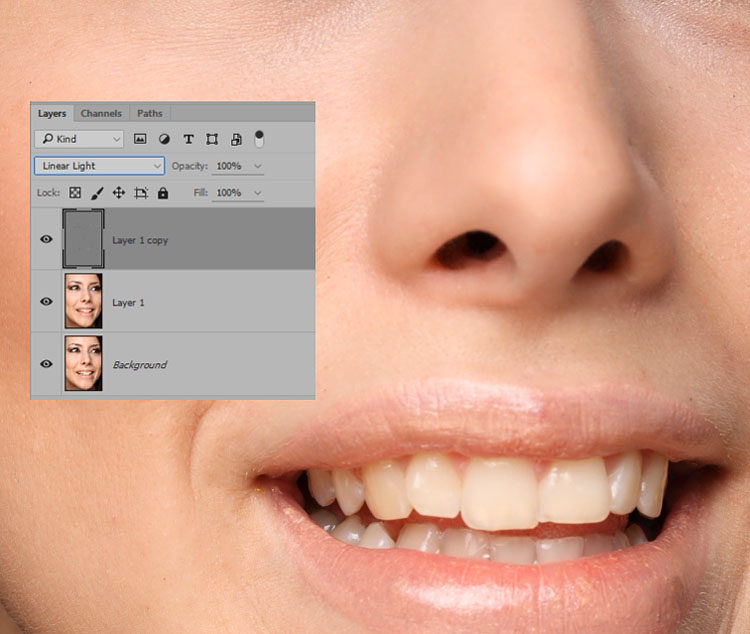
В открывшемся окне, как видно на следующей картинке, выбираем в пункте Layer слой с нижней частотой (Low) в режиме наложения Add (Добавление), включаем инвертирование, значение Scale устанавливаем на 2, Offset — 0. Нажимаем ОК.
Слою High меняем режим наложения на Linear Light (Линейный свет) и объединяем со слоем Low в группу.
Итак, подготовительный этап закончен. Далее будем работать только с нижней частотой (слой Low), не переживая за потерю детализации или текстуры, ведь она осталась на слое High.
Принцип дальнейшей работы прост: выравниваем необходимые (на субъективный взгляд каждого) области по яркости и цвету, тем самым визуально прикрывая на фотографии проблемные зоны — в нашем примере это участки под глазами, носогубные складки и т.д.
Для работы переходим на слой Low и берём инструмент Mixer Brush Tool (Микс-кисть, находится на панеле “Наборы кистей”).
Устанавливаем в верхней панели кисти значение в отрезке 20-22 для параметров Wet, Load, Mix, Flow. В нашем примере мы использовали 21.
В нашем примере мы использовали 21.
Границы кисти должны быть мягкими.
Во время работы с микс-кистью движения должны быть плавными. Направление — из зоны с хорошим паттерном на область, где нужно избавляться от проблем с яркостью или цветом. Таким образом проходим все необходимые места.
Если действия кажутся слишком внушительными, что сказывается на естественности и реализме фотографии, то значения непрозрачности группы можно снизить, например, до 60-70%.
На этом мы заканчиваем ретушь портрета, проделав первичную чистку базовыми инструментами Adobe Photoshop и используя приём “Частотное разложение”. В большинстве случаев на этом результате можно остановиться, однако существуют и другие механики ретуши, дополняющие этот приём или раскрывающиеся полноценно и самостоятельно. Например, техника Dodge and Burn, об одном варианте которой я расскажу вам в следующем материале.
Результат после первичной чистки и частотного разложенияВидеоурок
 youtube.com/embed/FB68JEg_rXk?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/FB68JEg_rXk?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Подписывайтесь на ТВОРЧmachine в социальных сетях:
Ретушь портрета. Метод частотного разложения.
Ретушь портрета. Метод частотного разложения.
Канал на YouTube
При обработке портрета все мы сталкиваемся с проблемой – как убрать дефекты кожи, сделать кожу ровной и бархатистой, а так же сохранить её текстуру. Думаю, многие из вас уже наслышаны о таком плагине для фотошопа, как Portraiture – это, как говорится, для особо ленивых 🙂 Быстро, удобно, но он делает кожу неестественной и пластмассовой. Я лично иногда его применяю, но крайне редко и с большой прозрачностью, бывает удобен при ростовых фотографиях, где лицо получается довольно маленьким. Но давайте поговорим о более профессиональном методе ретуши кожи, который хоть и более нудный и медленный, но позволяющий добиться превосходного результата.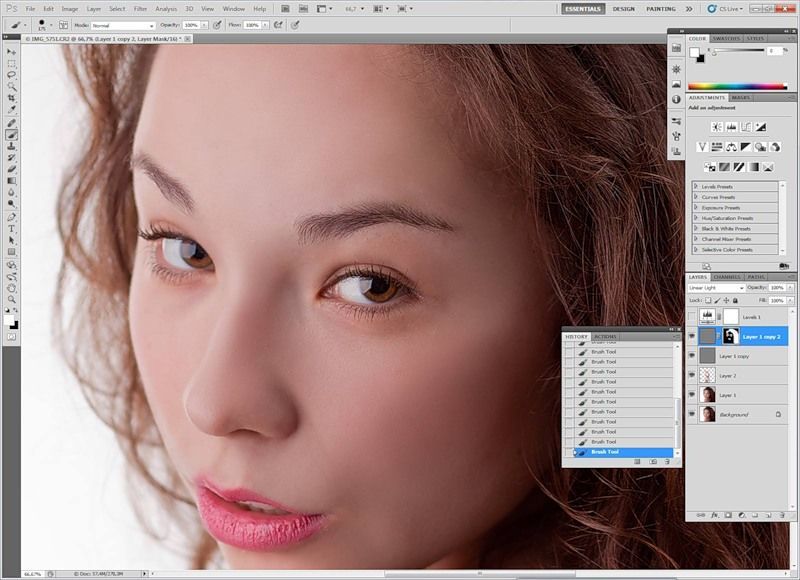
Итак, имеем фотографию слева, в ней уже сделана первичная свето- и цветокоррекция в лайтруме. Получим после наших манипуляций фотографию справа.
В сети довольно много разных способов этого метода ретуши, но я расскажу о том, какой быстрее, удобнее, проще и дает лучший результат.
На чем основывается этот метод: он основывается на том, что любую картинку можно разложить на 2 составляющие – на верхние и нижние частоты. И если «сложить» их обратно – получим исходную картинку. Тем самым разделяем картинку на слой, который сожержит текстуру кожи и слой, который содержит информацию о цвете, свето-теневых переходах и “форме”. Фильтр нижних частот в фотошопе – это фильтр Gaussian Blur. Верхних – High Pass, который мы будем применять через Внешний канал, т.к сам фильтр при “склеивании” дает неточности. Звучит сложно, но я постараюсь объяснить простым языком и на примерах)
Перейдем к практике:
- Допустим, у нас есть слой background. Делаем 2 копии его – я делаю это с помощью горячей клавиши Ctrl+J. Вы можете пойти в меню Layer – Duplicate Layer…
 Вы можете пойти в меню Layer – Duplicate Layer…
Вы можете пойти в меню Layer – Duplicate Layer…- Переименовываем их – нижнюю копию называем low, верхнюю – high.
- Отключаем видимость у верхнего слоя high, нажимая на иконку глаза.
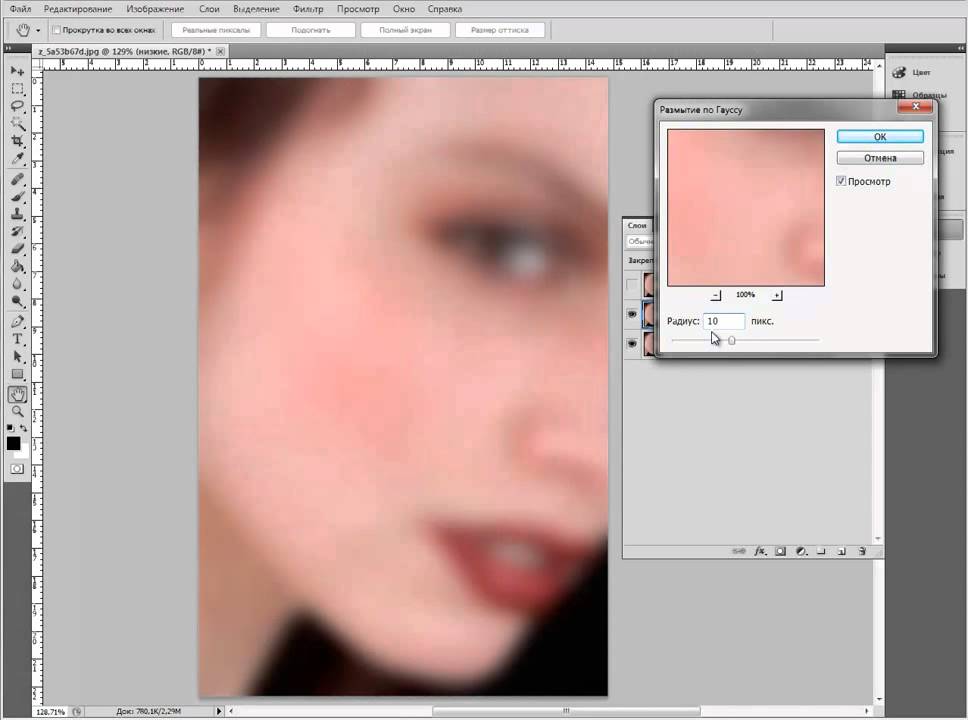
- Выбираем слой low, теперь работаем только с ним. Применяем к нему фильтр Gaussian Blur (Размытие по Гауссу). Для этого идем в Filter — Blur — Gaussian Blur… Тем самым мы создаем слой, который хранит “цвет и форму” изображения.
- Какой же радиус нам выбрать? Важно выбрать такой радиус размытия, чтобы текстура кожи уже была не видна, но все свето-теневые неровности от недостатков кожи сохранились. Такой радиус колеблется от 3px (там, где маленькая площадь лица/ростовой снимок — или маленький размер фото) до 15px(крупный потрет или бьюти, большой размер фото). В моем случае меня вполне устроил результат на 3,5px, т.к я кадрировала фото.
- Выбираем слой high и включаем его видимость.
- Теперь работаем с этим слоем, создавая “текстуру” изображения. Для этого идем в Image — Apply Image… (Изображение — Внешний канал…)
- Во вкладке Layer (Слой) кликаем и выбираем наш размытый слой — low.
- ВАЖНО:
1 случай — если вы работаете в 8-битном режиме, то настройки ставим — Blending — Substract (Наложение — Вычитание), Scale (Масштаб) — 2, Offset (Сдвиг) — 128.
2 случай — если вы работаете в 16-битном режиме, то настройки ставим — Blending — Add (Наложение — Добавление), Scale (Масштаб) — 2, Offset (Сдвиг) — 0. И нажимаем галочку Invert (инвертировать).
Как посмотреть, в скольки битном канале вы работаете? Обычно это пишется наверху рядом с названием открытой картинки через слэш (например, Beauty.psd (…/8) или (…\16)). Если не видите, то идите в Image — Mode — в открытой вкладке будет помечен галочкой режим, в котором вы сейчас работаете.
- Мы видим серое изображение. Меняем у слоя high режим наложения на Linear Light (Линейный свет).
- Предлагаю сгруппировать эти два слоя. Выделяем их и нажимаем Ctrl+G или идем в Layer — Group Layers (Слои — Сгруппировать слои). Эту группу называем “частотное разложение”.
Попробуйте выключить/включить видимость этой группы — вы поймете, что изображение не меняется, мы разложили изображение на 2 составляющие — на нижние частоты — размытый слой, где содержится информация о цвете и форме, и на верхние — где хранится только текстура изображения. Теперь мы можем работать с этими слоями по отдельности, не боясь “напортачить”).
Сначала боримся со всеми неровностями кожи — прыщи, шрамы, родинки, лишние волосы — информация о них хранится в слое текстуры, т.е. на слое high. Работать мы будем инструментом Штамп, с жесткостью 100%. Почему? Потому что это текстура кожи и на ней недопустимы “размытые края”, которые остаются после работы мягкой кистью или лечащей кистью, или той же заплаткой.
Размер подбираем чуть больше прыщика.
 Размер подбираем чуть больше прыщика.
Размер подбираем чуть больше прыщика.Сделали? Теперь выбираем рядом с прыщиком хорошую текстуру, т.е. ровную. Нажимаем Alt и кликаем. Тем самым мы выбрали место, откуда будем брать текстуру. Теперь смело кликаем на сам прыщик. Отлично!
Так проходимся по всей коже, удаляя всё то, что нам не нравится)
Заменили плохую текстуру хорошей, но пятна от этих прыщиков и неровностей всё равно остались. За них отвечает уже нижний слой, будем работать с ним.
Для этого выбираем слой low. Нам нужен инструмент Mixer Brush Tool с настройками наверху в 10%.
Что же он делает? В самом названии кроется суть его работы — он смешивает близлежащие цвета там, где вы проводите кистью. Таким образом, немного поводив кистью на месте прыщика и в его окрестностях, мы смешаем цвет так, что на его месте будет ровная поверхность вместо пятна. Попробуйте.
- Таким образом проходимся по всем пятнам на лице, выравнивая фактуру кожи и создавая ровный тон лица, но не переусердствуйте.

Вот в принципе и весь метод частотного разложения)
Чтобы добиться лучшего результата, есть несколько усовершенствований этого метода, о которых я сейчас вам поведаю.
- Смягчение кожи.
Для этого перед тем, как вы будете работать со слоем low, сделайте его копию и примените к копии фильтр Gaussian Blur с размытием не более 10px, так, чтобы вы наглядно видели, как смягчается кожа.
Теперь создадим маску слоя. Для этого жмем соответствующую иконку.
Далее инвертируем маску. Жмем Ctrl+I или идем в Image — Adjustments — Invert.
Теперь берем белую кисть и рисуем там, где нам нужно смягчение, а именно — лоб, щеки, нос, подбородок, но не заходим на глаза, губы или край лица. В итоге маска будем примерно такая:
Я снизила непрозрачность до 65%, вы же делайте это по своему усмотрению)
- Резкость и лучшее видение всех недостатков при ретуши.
Данный действия делаем до того, как мы начали работать с текстурой.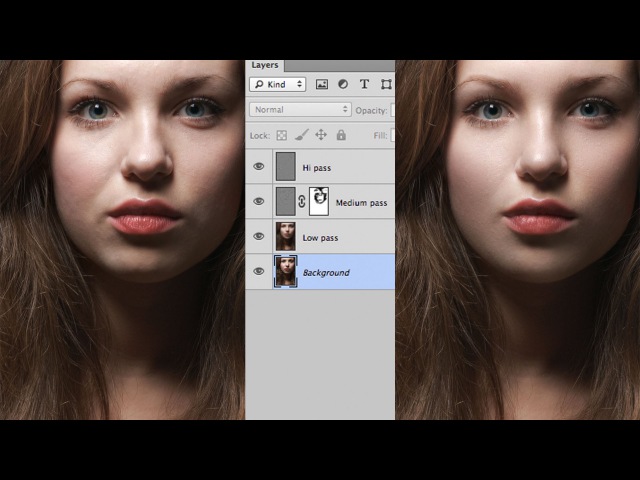
Делаем копию слоя high нажатием Ctrl+J. Создаем обтравочную маску для него. Для этого выбираем слой high copy, зажимаем Alt и ведем курсор на положение между этими слоями, до возникновения такого значка. Кликаем.
Меняем его режим наложения на Normal.
Теперь все действия со штампом мы будем проводить на нем.
Чтобы лучше видеть все недостатки, создадим вспомогательный слой кривых. Нажимаем на иконку и выбираем Curves.
Переименовываем этот слой в contrast, ибо этот слой действильно повышает контраст. И создаем для него обтравочную маску, как мы это уже делали выше.
Далее выставляем в кривых такие значения:
Для нижней точки: Input — 97, Output — 0.
Для верхней точки: Input — 158, Output — 255.
Видим, как это влияет на наше изображение:
Оно стало слишком резким, поэтому убавляем непрозрачность примерно до 50%, чтобы мы хорошо видели все неровности.
Когда закончите ретушь — убавьте непрозрачность примерно до 1-5%, если вы хотите повысить резкость всего изображения, если же вам нравится исходная картинка — то либо выключите видимость этого слоя, либо вообще его удалите. Вот и всё)
Вот и всё)
P.S. Я все еще недовольна результатом, т.к. на коже видны некоторые пятна. Чтобы их удалить, я пользуюсь методов осветления и затемнения, в народе он более известен как метод Dodge and Burn, о котором я рассказала в этой статье. После него получаем гораздо более привлекательную картинку. Далее я сделала финальную цветокоррекцию и вот результат: исходная картинка, после частотного разложения и финальная:
Про методы упрощения и ускорения процесса можно узнать в этом видео:
И почитать в в этой статье
Ставь лайк, если статья была полезна (:
Частотное разложение. ULTIMATE | Виртуальная школа Profile
Частотное разложение. ULTIMATE
Цикл завершен. Начавшаяся 4 года назад история подошла к логическому концу. Я не изобретал этот прием, мне просто удалось вытащить его из узкого кулуарного круга «крутых профи» и запустить в широкие массы. Само название «частотка» — яркое тому доказательство. Огромное спасибо Александру Миловскому за подсказку, позволившую мне открыть Америку через форточку (так мой дед называл изобретение для себя лично чего-либо уже известного окружающим). Именно из его статьи шагнул в массы термин «частотное разложение».
Само название «частотка» — яркое тому доказательство. Огромное спасибо Александру Миловскому за подсказку, позволившую мне открыть Америку через форточку (так мой дед называл изобретение для себя лично чего-либо уже известного окружающим). Именно из его статьи шагнул в массы термин «частотное разложение».
1. ТЕОРИЯ
Разложение в спектр.
В 1807 году Жан Батист Жозеф Фурье подготовил доклад «О распространении тепла в твёрдом теле», в котором использовал разложение функции в тригонометрический ряд
При таком преобразовании функция представляется в виде суммы синусоидальных колебаний (гармоник) с различной амплитудой
Любой сигнал может быть представлен в таком виде, а все образующие его гармоники вместе называются спектром
В 1933 году Владимир Александрович Котельников сформулировал и доказал теорему, согласно которой любой сигнал с конечным спектром может быть без потерь восстановлен после оцифровки, при условии, что частота дискретезации будет как минимум в два раза выше частоты верхней гармоники сигнала
Что такое пространственные частоты.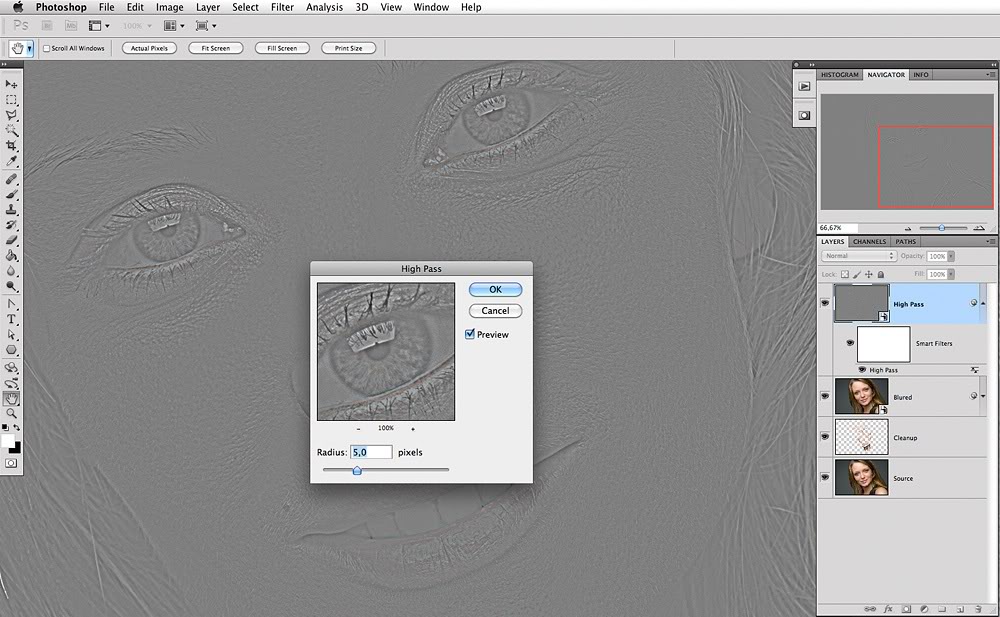
Частота с которой меняется яркость при перемещении по горизонтали или вертикали
Изображение — это двумерный сигнал (яркость меняется при перемещении по горизонтали и вертикали), поэтому общая решетка образуется из двух решеток различных ориентаций — горизонтальной и вертикальной
Чем выше частота, тем быстрее меняется яркость, тем мельче детали которые она задает
Самые мелкие детали — это перепады яркости на контрастных контурах
Разложение на полосы частот.
Для эффективной обработки сигнала нет необходимости раскладывать его в спектр, достаточно разложить его на несколько полос, содержащих все гармоники ниже или выше определеной частоты
Самые низкие частоты задают общее распределение яркости и, как следствие, цвета
Средние частоты уточняют эту картинку принося основные объемы объектов
Верхние частоты добавляют самую мелкую детализацию — фактуру поверхностей
Дополнительные материалы:
Алексей Шадрин. «Управление визуальным объемом изображений»Александр Миловский. «Муар нам только снится»
«Муар нам только снится»2. ПРОСТОЕ РАЗЛОЖЕНИЕ НА 2 ПОЛОСЫ ЧАСТОТ
Фильтры нижних и верхних частот.
Gaussian Blur — фильтр нижних пространственных частот
Чем больше Raduis, тем более крупные детали убираются, тем ниже оставшиеся частоты
High Pass — фильтр верхних пространственных частот, дополнительный к Gaussian Blur
High Pass показывает детали, которые убрал Gaussian Blur при том же значении Radius
Эти детали отображаются в виде отклонения от средне-серого цвета (отклонения от средней яркости в каждом канале)
Сложение исходного изображение из частотных полос.
Добавить эти отклонения к исходному изображению может режим Linear Light
Контраст ВЧ-слоя надо понизить в два раза вокруг средней яркости (тон 128), чтобы скомпенсировать заложенное в Linear Light удвоение
Это можно сделать при помощи кривых (Curves) подняв черную точку в позицию (0; 64) и опустив белую в позицию (255; 192)
Можно понизить контраст при помощи Brightness/Contrast с установкой Contrast -50 и активированным ключем Use Legacy
Вместо понижения контраста можно уменьшить до 50% непрозрачность слоя, но в этом случае регулятор Opasityиспользовать нельзя, а нужно воспользоваться регулятором Fill
Дополнительные материалы:
Андрей Журавлев. «Ретушь портрета на основе частотного разложения»
«Ретушь портрета на основе частотного разложения»3. DODGE & BURN
Идеология Dodge & Burn.
Основная идея этой техники: ручное осветление излишне темных и затемнение слишком светлых участков для придания объекту более гладкой и правильной формы
Таким же образом усиливаются или дорисовываются недостающие объемы
Классически реализуется при помощи инструментов Dodge Tool и Burn Tool, но эти инструменты допускают только деструктивную обработку
Может быть реализована при помощи режимов наложения или корректирующих кривых с рисованием по макске слоя
Реализация Dodge & Burn при помощи режимов наложения.
Для сильной перерисовки свето-теневого рисунка используются режимы наложения Multiply и Screen
Рисование производится на пустых или залятых нейтральными для данных режимов цветом слоях
Основным преимуществом такой работы является большая сила воздействия: Multiply способен затемнять даже белый объект, а Screen осветлять даже черный
Дополнительным плюсом является возможность работать разным цветом на одном слое и простота выбора цвета: его можно брать с самого изображения
Минусом (особенно для начинающих) является уже упомянутая сила воздействия, заставляющая точно контролировать свои движения
Для легкой финальной правки применяют слой в режиме Soft Light (прозрачный или залитый средне-серым)
Плюсами являются: мягкость и визуальная однородность воздействия; ограниченный диапазон воздейстывий; отсутствие воздействия на белые и черные участки
Реализация Dodge & Burn при помощи кривых.
Затемнение и осветление производится при помощи корректирующих слоев кривых (Curves), а необходимые участки прорисовываются по их маскам
При затемнении происходит повышение, а при осветлении понижение, насыщенности изображения. Для их компенсации к каждому слою кривых через маску вырезания (Create Clipping Mask) добавляется слой Hue/Saturation
К плюсам метода можно отнести большую (по сравнению с использованием режимов наложения) гибкость последующих настроек
Минусом является невозможность вносить разные оттенки цвета при помощи одного корректирующего слоя
Для самостоятельного изучения:
Алиса Еронтьева и Дмитрий Никифоров. «Портретная ретушь»4. ИНСТРУМЕНТЫ ИХ НАСТРОЙКИ
Почему выгодно править частотные полосы по отдельности.
При ретуши необходимо согласовывать цвет и его переходы с одной стороны и фактуру поверхности с другой
При исправлении формы крупных объектов выгодно использовать пониженную непрозрачность
Для сохранения мелких объектов (фактура поверхности) необходимо использовать 100% непрозрачность
Мягкая граница кисти у штампа — вынужденный компромисс между этими двумя требованиями
Жесткий стык между однородными однотипными фактурами заметен не будет
Выбор радиуса при разложении на две полосы частот.
Для Gaussian Blur выгодно задавать большой радиус, чтобы максимально убрать фактуру
Для High Pass выгодно задавать малый радиус, чтобы не пропустить объемы
Конкретное значение выбирается как компромиссный вариант между этими двумя условиями
При этом учитывается детали какой крупности мы относим к фактуре
Визуализация при выборе радиуса разложения.
Радиус Gaussian Blur удобнее подбирать плавно увеличивая его, пока не исчезнут ненужные детали
Радиус High Pass удобнее подбирать плавно уменьшая его, пока не пропадут ненужные объемы
Если более важной является форма, радиус удобнее подбирать ориентируясь на содержимое НЧ (размытая картинка)
Если более важной является фактура поверхности, радиус удобнее подбирать ориентируясь на содержимое ВЧ («хайпасная» картинка)
Зависимость радиусов от размера лица и крупности дефектов.
Пропорции среднего лица (ширина к высоте) составляют примерно один к полутора
При вычислении радиусов удобнее отталкиваться от высоты лица, так как она меньше зависит от ракурса съемки
Для удаления аккуратной фактуры кожи необходимо взять значение Radius порядка 1/280 — 1/250 от высоты лица
Для удаления мелких дефектов (прыщи, морщины и т. п.) необходимо взять значение Radius порядка 1/100 — 1/120 от высоты лица
п.) необходимо взять значение Radius порядка 1/100 — 1/120 от высоты лица
Для удаления крупных дефектов (подглазины, шрамы и т.п.) необходимо взять значение Radius порядка 1/50 — 1/60 от высоты лица
5. РЕТУШЬ ПРИ РАЗЛОЖЕНИИ НА 2 ПОЛОСЫ ЧАСТОТ
Ретушь НЧ-составляющей — исправление формы.
Находящуюся на НЧ слое форму удобно ретушировать при помощи инструментов Clone Stamp, Brush и Mixer Brush
Штампом работаем с мягкой кистью и пониженной непрозрачностью
Можно работать на новом прозрачном слое с настройкой штампа Sample: Current & Below
При этом на экран можно вывести общий вид картинки, а не только НЧ слоя.
Кисть (Brush Tool) удобно использовать для закрашивания локальных дефектов (пробойные блики, проваальные тени и т.п.) телесным цветом
Mixer Brush используется для быстрого разглаживания лишних объемов
Ретушь ВЧ-составляющей исправление фактуры.
Работаем штампом с жесткой кистью и 100% непрозрачностью
Можно работать на новом прозрачном слое с настройкой штампа Sample: Current & Below и отображением только ВЧ слоя
Чтобы ретушировать глядя на финальную картинку надо работать на самом ВЧ слое (его копии) с настройкой штампа Sample: Current Layer
Чтобы иметь возможность откатиться к исходному состоянию ретушь проводят на копии слоя ВЧ с применением к нему команды Create Clipping Mask
Для лучшего контроля над деталями можно временно включить корректирующий слой кривых, повышающий контраст ВЧ составляющей
При отсутствии на изображении необходимой текстуры можно перенести ее с другой фотографии
Как работает Healing Brush.
На НЧ слое после размытия на участках рядом с контрастной границей появляется цвет соседней области
На ВЧ слое вдоль контрастных границ появляются ореолы противоположных цветов
Если в процессе ретуши ВЧ слоя убрать ореол на финальной картинке на этом участке появится цвет соседней области
Healing Brush переносит фактуру с донорской области, подгоняя цвет и яркость под ретушируемого участка под цвет и яркость его окрестностей
Его работа построена на алгоритме частотного разложения, а значение радиуса привязано к размер кисти
6. ОТДЕЛЬНЫЕ ПРИЕМЫ РЕТУШИ
ОТДЕЛЬНЫЕ ПРИЕМЫ РЕТУШИ
Как побрить человека.
Вынести волоски (щетину) на ВЧ слой и заменить их фактурой чистой кожи
Если щетина была темная, поправить цвет на НЧ слое
Внимательно следите за фактурой, она сильно отличается на разных участках лица
«Брить» мужчину тяжело, поскольку на лице не хватает нужной фактуры
При необходимости нужную фактуру кожи можно взять с другой фотографии
Борьба с пробойными бликами. Ретушь НЧ.
Изображение раскладывается на две полосы с установками обеспечивающими полный переход фактуры кожи на ВЧ слой
На НЧ слое участки пробойных бликов закрашиваются цветом кожи
При необходимости на них наносится свето-теневой рисунок передающий объем объекта
Борьба с пробойными бликами. Ретушь ВЧ.
Если блик пробойный и вообще не содержал фактуры, она переносится с целых участков кожи
Если блик близок к пробойному и фактура кожи все-таки содержится, после ретуши НЧ она визуально усилится
Чтобы смягчить этот эффект можно наложить на нее фактуру с более гладких участков на отдельном слое с пониженной непрозрачностью
7. «ЧЕСТНОЕ» РАЗЛОЖЕНИЕ НА 2 ПОЛОСЫ ЧАСТОТ
«ЧЕСТНОЕ» РАЗЛОЖЕНИЕ НА 2 ПОЛОСЫ ЧАСТОТ
Ошибка High Pass.
Максимальный диапазон разностей яркости от -256 (вычитаем белый из черного) до 256 (вычитаем черный из белого) составляет 512 тоновых уровней
Максимально возможные отклонения от средней яркости от -128 (затемнение) до 127 (осветление)
При наличии мелких деталей на массивном фоне отличающихся по яркости более чем на 128 уровней High Pass ошибается
Обычно это случается на точечных бликах расположенных на темном объекте
Чем больше радиус размытия, тем больше сама ошибка и вероятность ее появления.
На практике, при малых радиусах разница является «гомеопатической» и рассматривать ее как реальную проблему можно только с академической точки зрения
При больших радиусах ошибка составляет реальную проблему, поскольку «гасит» мелкие блики
Создание ВЧ составляющей вычитанием НЧ из оригинала.
Альтернативой High Pass является наложение на исходное изображение размытой версии при помощи команды Apply Image в режиме Subtract с установками Scale:2 Offset:128
В поле Offset (смещение) задается значение яркости вокруг которого будет откладываться результат вычитания
В поле Scale устанавливается во сколько раз будет уменьшаться результат вычитания перед добавлением к значению Offset
Диапазон установок Scale от 1 до 2, то есть контраст можно понизить максимум в 2 раза
Применять корректирующий слой понижающий контраст в этом случае не нужно, поскольку он уже понижен установкой Scale:2
Особенности разложения 16-битных изображений.
При вычислении ВЧ через команду Subtract у 16-битных изображений появляется ошибка величиной в 1 восьмибитный (128 шестнадцатибитных) уровень
Вероятно, это связано с тем, что реально вычисления происходят в пятнадцатибитном виде
Чтобы избежать этой ошибки при работе в 16-битном режиме вместо команды Subtract используют команду Add с активированным ключом Invert и установками Scale:2 Offset:0
Использование Surface Blur для получения НЧ составляющей.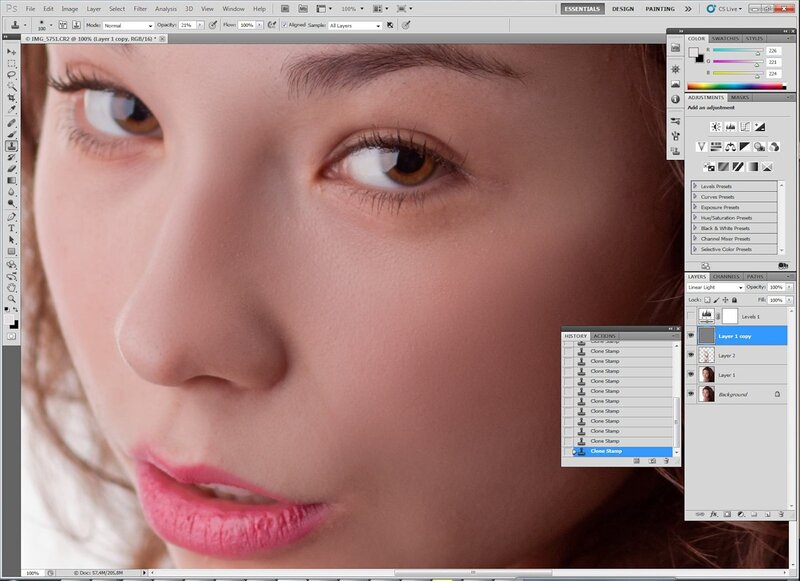
В случае применения для получения НЧ составляющей Gaussian Blur вдоль контрастных границ создаются сильные ореолы
Ретушь в области ореолов может привести к «затягиванию» на объект цвета соседнего фона
Проблема проявляется тем более сильно, чем больше радиус размытия, поскольку в этом случае ореолы становятся более массивными и плотными
Чтобы избежать такой проблемы НЧ составляющую можно создавать при помощи фильтра Surface Blur
Границы, имеющие перепад яркости больше уровня установленного регулятором Threshold, не размываются
На практике удобнее всего подобрать значение Radius при установленном на максимум Threshold, а потом уменьшать значение Threshold до восстановления контрастных границ
8. АВТОМАТИЗАЦИЯ ПРОЦЕССА
Запись универсального экшена для разложения на 2 полосы частот.
Все операции выполняются со слоями, созданными самим экшеном
Слой создается командой Layer > New Layer и сразу переименовывается
Текущее изображение помещается на него при помощи команды Image > Apply Image с установкой Layer: Merged
Переключения между слоями выполняются при помощи шоткатов «Alt»+«[» и «Alt»+«]»
Для возможности переключения вместо отключения видимости слоя его непрозрачность уменьшается до нуля
При необходимости перемещение слоев выполняются командами Layer > Arange
В качестве подсказки перед применением Gaussian Blur в экшен вставляется команда Stop с комментариями по подбору радиуса
При регулярном применении Stop можно деактивировать или удалить
Преимущества «честного» разложения при работе с экшенами.
При записи экшена количество стандартных операций не является критичным
При этом важно минимизировать количество операций, требующих участия пользователя
Вычисление ВЧ составляющей через наложение НЧ на копию исходного слоя избавляет пользователя от задания радиуса для фильтра High Pass
Дополнительным плюсом такого метода является возможность применить для размытия не Gaussian Blur, а какой-нибудь другой фильтр
Создание набора экшенов для разложения на 2 полосы.
Сделать набор экшенов с жестко заданными значениями радиуса можно на основе универсального экшена
Для этого нужно убрать команду Stop, отключить диалоговое окно в Gaussian Blur и настроить его радиус на требуемый
Для удобства последующей работы с файлом к названиям слоев Low и High можно сразу добавить приписку со значением радиуса размытия
Экшен для пакетной обработки с настройкой по первому кадру.
При обработке серии фотографий с одинаковой крупностью объектов было бы удобно один раз вручную подобрать нужный радиус разложения, а потом применять его ко всей серии
Это можно сделать, если вместо прямого вызова конкретного фильтра вписать в экшен команду вызова последнего использовавшегося фильтра
Теперь достаточно один раз вызвать нужный фильтр (в рамках стандартного экшена или отдельно), настроить его параметры и он будет применяться при всех следующих запусках экшена
9. РАЗЛОЖЕНИЕ НА 3 ПОЛОСЫ ЧАСТОТ
РАЗЛОЖЕНИЕ НА 3 ПОЛОСЫ ЧАСТОТ
Зачем раскладывают картинку на три полосы.
Чаще всего задача такого разложения — вынести все дефекты в среднюю полосу частот
Таким образом можно бороться с объектами определенного типоразмера, например веснушками
Кроме того, в средних частотах находится большинство «старящих» элементов: глубина морщин, жилистость, вены, провисания, мешки под глазами и т.п.
Реже ретушируются все три полосы, в этом случае процесс аналогичен разделению на 2 полосы, но позволяет проще работать объектами разного типоразмера
Как это сделать.
Для НЧ увеличиваем радиус Gaussian Blur пока не останется чистая форма
Для ВЧ уменьшаем радиус High Pass пока не останется чистая фактура
Создаем между нами слой средних частот применив к нему сначала High Pass с радиусом который использовался для создания НЧ, а потом Gaussian Blur с радиусом который использовался для создания ВЧ
Универсальное правило: High Pass следующего слоя имеет такой же радиус, как Gaussian Blur предыдущего
Теперь можно ретушировать средние частоты не обращая внимание не только на фактуру, но и на разницу цвета исходной и ретушируемой области
При «честном» разложении средние частоты получаются вычитанием из исходного изображения низких и высоких
Автоматизация разложение на три полосы.
Для создания ВЧ удобно использовать High Pass, поскольку он позволяет более наглядно подобрать радиус
В процессе подбора уменьшаем радиус High Pass пока на ВЧ не останется чистая фактура
Вместо High Pass можно использовать Gaussian Blur с визуализацией ВЧ составляющей
Слой средних частот можно получить вычитая из исходного изображения верхние и нижние частоты
10. УПРОЩЕННЫЙ МЕТОД РЕТУШИ СРЕДНИХ ЧАСТОТ (INVERTED HIGH PASS)
Почему можно упростить ретушь средних частот.
Ретушируя средние частоты мы прежде всего убираем лежащие в них излишние локальные объемы
Это можно сделать проще, не раскладывая изображение на три полосы, а выделить среднюю и вычесть ее из исходника
Вычитание должно быть локальным: только на участках где присутствует лишний объем, пропорционально степени его подавления
Как это сделать.
Подбирать радиус для High Pass удобнее через Gaussian Blur (через НЧ составляющую) и наоборот
Делаем копию исходного слоя
Вызываем Gaussian Blur, плавно увеличиваем радиус пока не исчезнут ненужные детали, запоминаем его значение и нажимаем Cansel
Вызываем High Pass, плавно уменьшаем радиус пока не пропадут ненужные объемы, запоминаем его значение и вводим радиус подобранный на предыдущем шаге
Применяем Gaussian Blur с радиусом подобранным на предыдущем шаге
Инвертируем изображение
В два раза понижаем контраст вокруг средней точки
Переключаем режим наложения на Linear Light
На слой вычитающий средние частоты из исходного изображения набрасываем черную маску
Белой кистью по маске прорисовываем те участки, на которых нужно подавить крупные детали
Автоматизация процесса.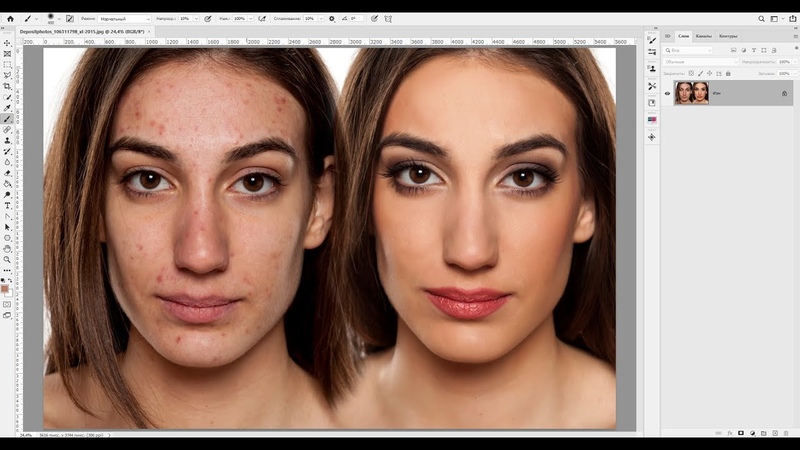
Все рутинные операции записываются в экшен
Полоса средних частот получается вычитанием из исходного изображения НЧ и ВЧ полос с подобранными пользователем радиусами
За счет этого визуализация оказывается наиболее комфортной
Подбор верхнего радиуса можно делать после наложения на исходное изображение инвертированной СЧ+ВЧ составляющей. В этом случае используется Gaussian Blur и на размытой картинке начинает проступать чистая фактура
Чем приходится расплачиваться за скорость.
Результат ручной ретуши выглядите естественно прежде всего из-за сохранения мелких неоднородностей
За скорость и простоту приходится расплачиваться механистически правильной формой объектов, что визуально удешевляет работу
Соотношение радиусов обычно выбирают 1:3 или меньше, иначе результат будет выглядеть слишком неестественным
Для более тонкой работы соотношение радиусов берут примерно 1:2 и производят несколько циклов разложения с разными значениями вилки
При ретуши второстепенных участков можно брать соотношение 1:4 и даже больше
Для самостоятельного изучения:
Евгений Карташов.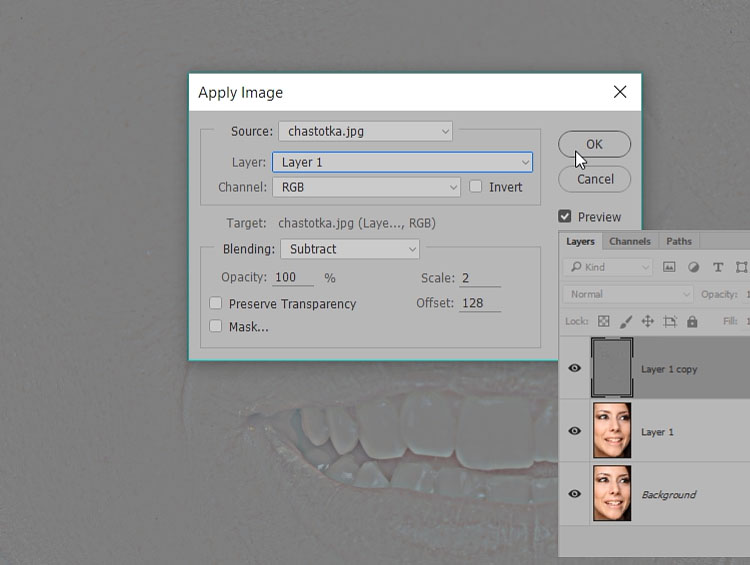 «Рецепты частотного разложения»
«Рецепты частотного разложения»11. ЧАСТОТНОЕ РАЗЛОЖЕНИЕ И ДРУГИЕ ИНСТРУМЕНТЫ PHOTOSHOP
Средние частоты и Clarity.
Алгоритм работы Clarity строится на усилении (ослаблении) средних пространственных частот
При этом работа идет только по яркостной составляющей изображения
Повышение и ослабление Clarity не симметрично
Инструмент использует интеллектуальное размытие с сохранением контрастных контуров напоминающее Surface Blur, но не совпадающее с ним
При умеренных значениях можно рекомедовать использование Clarity в конвертере, при условии, что в дальнейшем изображение не будет подвергаться «сильной» обработке
Высокие частоты и повышение резкости.
Искусственное повышение резкости есть ни что иное, как усиление самых верхних из содержащихся в изображении частот.
При подготовке пейзажей основной проблемой является замыливание (исчезновение) сверх мелкой детализации (трава) вследствии нехватки разрешения.
Аналогичная проблема встает при подготовке изображений с мелкими деталями для размещения в интернете
Создать визуально ощущение наличия сверх мелких деталей можно добавив в изображение мелкий шум, согласованный с его элементами
Для этого повышаем резкость классическим способом, но оставляем это повышение только на низко контрастных областях
Проще всего это сделать используя Surface Blur в качестве фильтра, создающего нерезкую маску
12. В ЗАВЕРШЕНИИ РАЗГОВОРА
Для чего еще можно применять частотное разложение
Частотное разложение — это универсальный метод применимый к любому жанру фотографии
Убирать складки на ткани или других материалах
С его помощью можно смягчать слишком жесткие тени
Избавляться от разводов оставшихся после общей ретуши
Решать любые задачи, требующие различной работы с общей формой и мелкими деталями
Почему после частотного разложения картинка выглядит плохо?
Ретушь — это процесс не поддающийся автоматизации
Частотное разложение не делает ретушь за вас, оно лишь упрощает решение некоторых проблем
Увлекшись возможностью решить все «несколькими размашистыми мазками», при использовании частотного разложения ретушеры нередко позволяют себе работать халтурно
Будьте честны перед собой, не сваливайте собственные ошибки и халтуру на «плохую методику»
Чтобы избежать такой ловушки можно разделить процесс на два этапа
При помощи частотного разложения быстро поправить форму и разобраться с сильными огрехами фактуры (пробойные блики, грубая фактура и т. п.)
п.)
Последующую доработку производить при помощи привычных реализаций Dodge & Burn, чтобы обеспечить остаточную неоднородность и естественность изображения
Для самостоятельного изучения:
ModelMayhem.com — RAW! Beauty Robot.Сергей Брежнев «Частотное разложение vs Dodge&Burn»Метод частотного разложения · Мир Фотошопа
Профессиональные ретушёры использую много разных техник ретуши кожи. В этом уроке Вы изучите одну из базовых техник ретуши называемую частотным разложением. Она используется для быстрого разглаживания кожи без потери детализации.
Что такое частотное разложение?
Частотное разложение — это жаргон, используемый в мире ретуши, для описания техники разглаживания кожи. Техника основывается на разделении изображения на две «частоты».
- Слой низкой частоты: слой для смягчения, на котором находятся только тона и оттенки.
- Слой высокой частоты: слой резкости и мелких деталей.
Как разгладить кожу аэрографом, используя метод частотного разложения?
1.
 Подготовьте слой к обратимому редактированию
Подготовьте слой к обратимому редактированиюПреобразуйте слой фотографии в смарт-объект. Благодаря ему Вы сможете изменять настройки фильтров в любое время.
Создайте две копии слоя. Верхнюю назовите «High Frequency Layer», а нижнюю — «Low Frequency Layer».
2. Создание слоя высокой частоты
Выберите верхний слой и примените фильтр High Pass (Filter ? Other ? High Pass). В результате получится серый слой с эффектом тиснения на деталях. Установите радиус на 3 пикселя.
Установите режим наложения Linear Light и получите очень сильную резкость. Этот слой поможет восстановить детализацию на фотографии.
3. Традиционный и современный вариант размытия
Обычно к слою с низкой частотой применяют фильтр Gaussian Blur, который противоположен фильтру High Pass. Вместо повышения детализации он размазывает изображение так, чтобы стали видны только тона.
Однако традиционный способ не всегда даёт хорошие результаты. Он создаёт эффект рассеянного свечения и делает кожу искусственной. Поэтому вместо традиционного метода мы будем использовать современный, подразумевающий применение фильтра Surface Blur. Он даёт более реалистичное изображение и сохраняет края объектов чёткими. Ниже можете сравнить два фильтра:
Поэтому вместо традиционного метода мы будем использовать современный, подразумевающий применение фильтра Surface Blur. Он даёт более реалистичное изображение и сохраняет края объектов чёткими. Ниже можете сравнить два фильтра:
4. Создание слоя низкой частоты
Выберите нижнюю копию и примените фильтр Surface Blur (Filter ? Blur ? Surface Blur).
5. Настройка слоя высокой частоты
Уменьшите непрозрачность верхнего слоя, чтобы уменьшить чрезмерную резкость. Начните с 50%.
6. Настройка слоя низкой частоты
Вернёмся к нижнему слою. Кликните дважды на названии фильтра, чтобы открыть настройки. Установите Threshold на максимум и настройте радиус так, чтобы тона кожи стали плавными и всё изображение размытым.
Уменьшите Threshold, чтобы детали стали снова появляться. Возможно Вам потребуется несколько раз перенастраивать фильтр.
7. Объединение слоёв
Оба слоя поместите в одну группу (Ctrl + G) и назовите её «Frequency Separation».
8. Маска группы
К группе добавьте маску и залейте её чёрным цветом. Белой кистью верните эффект разглаживания на отдельные участки лица.
<iframe src=»https://www.youtube.com/embed/R8WVR2VroSc?rel=0″ frameborder=»0″ allowfullscreen></iframe>
На этом можно закончить урок. Так как мы работали со смарт-объектом, Вы в любой момент можете открыть его и изменить изображение. Если вдруг решите почистить кожу инструментом Spot Healing Brush Tool, лучше работать на отдельном слое. В настройках инструмента нужно включить Sample All Layers.
<iframe src=»https://www.youtube.com/embed/vgUkq-sxG7A?rel=0″ frameborder=»0″ allowfullscreen></iframe>
Результат до и после:
Урок Photoshop • Выравнивание тона кожи методом частотного разложения
Важную часть в ретуши портретов занимает детализация кожи. Одним из наиболее удобных способов обработки является метод частотного разложения. Он очень прост, если работать с ним чётко по инструкции, и в последующем довести этот алгоритм действия до автоматизма.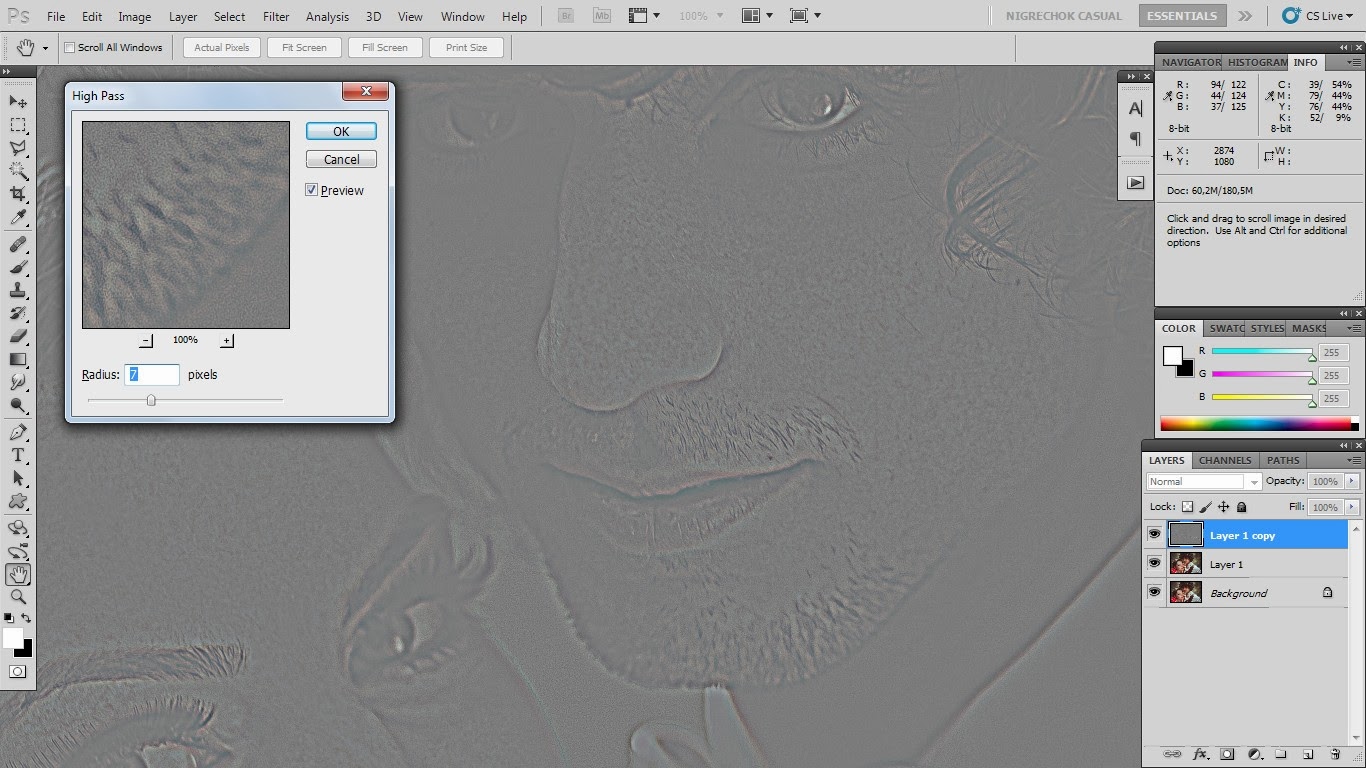
До :
и после:
Метод частотного разложения работает безотказно, даже в самых сложных ситуациях, когда фотограф не знает, с чего начать. Для ретуши портретов важно охранить мелкие детали. Поэтому лучше использовать метод частотного разложения, нежели обработку с помощью умных инструментов.
ПОДГОТОВКА
Для начала проведем с изображением ряд предварительных обязательных процедур. Разделим его на те самые частоты, составные части. Приступаем.
1. Первым делом создаем 2 слоя, копии исходного изображения. Сделать это можно разными способами: например, кликнув правой клавишей мыши и выбрав «создать дубликат слоя» или нажав сочетание клавиши на клавиатуре Ctrl+J. Сразу дадим слоям имена и назовём их low и hi, впоследствии это и будут наши низкие и высокие частоты.
Делать копии слоя — это очень простая и полезная привычка, особенно при ретушировании. У вас всегда будет возможность обратиться к исходнику, если что-то пойдёт не так.
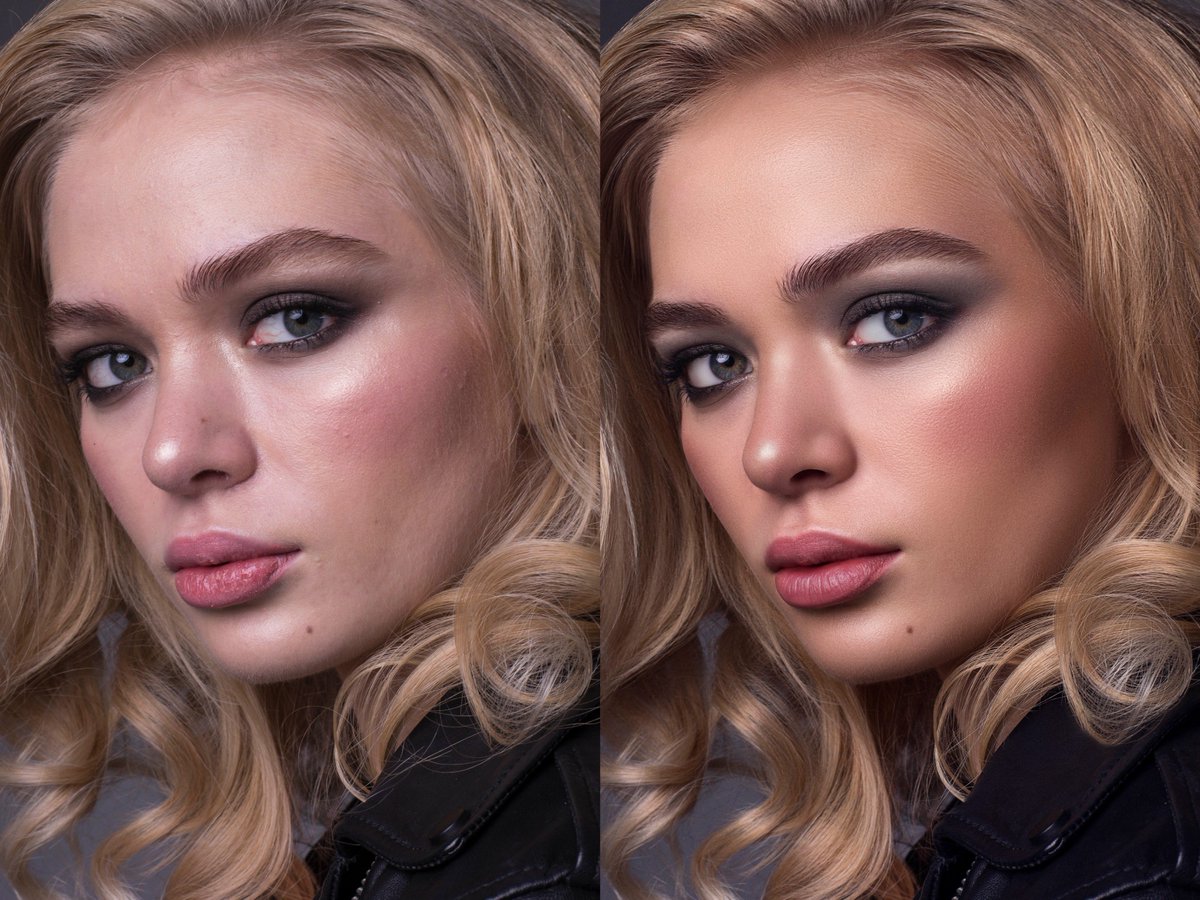
2. Верхнему слою hi выключаем видимость, им мы займёмся позже. Переходим к слою low.
3. Этот слой hi необходимо размыть с помощью фильтра Gaussian Blur (Размытие по Гауссу), в котором необходимо выбрать радиус размытия. Нам нужно убрать неровности кожи, мелкие морщинки, пыль и тому подобное. Но глаза, нос и брови мы, скорее всего, захотим оставить. Поэтому, начиная увеличивать радиус, внимательно смотрим, как меняется картинка. Результат очень зависит от размера исходника, а также от того, сколько места занимает человек в кадре. Для этого изображения давайте остановимся на отметке 12,5px для радиуса размытия. Важно запомнить выбранное значение, это число пригодится нам уже в следующем шаге.
Со временем вы научитесь определять подходящий радиус сразу.
4. Теперь переходим к верхнему слою hi. Нам нужно скомпенсировать изображение таким образом, чтобы при наложении на наш размытый слой low в результате получить исходную картинку. Для этого используется фильтр, который в совокупности с подходящим режимом наложения даст эффект, противоположный Gaussian Blur, который мы использовали ранее. И имя этому фильтру High Pass (Фильтр — Другое — Цветовой контраст).
Для этого используется фильтр, который в совокупности с подходящим режимом наложения даст эффект, противоположный Gaussian Blur, который мы использовали ранее. И имя этому фильтру High Pass (Фильтр — Другое — Цветовой контраст).
В открывшемся окне High Pass всего один регулируемый параметр, и это опять радиус. Здесь нужно выставить значение из прошлого шага. Выставляем 12,5px, именно на столько мы размывали слой low.
5. Переводим слой hi в режим наложения Linear Light (Линейный свет).
Этот режим работает таким образом, что серый цвет становится прозрачным, а любые отклонения от серого драматически увеличивают яркость и контраст. Результат после наложения на размытый слой получается ровно в два раза более контрастный, чем оригинальный снимок.
6. Уменьшить контраст можно разными способами, я предпочитаю использовать корректирующие слои, т. е. слои с настройками (например, слой с кривыми). Такой способ легко позволяет на время отключать понижение контраста. С контрастной версией очень удобно работать во время ретуши, сразу выделяются все неровности и детали, которые можно случайно пропустить, глядя на исходный вариант.
С контрастной версией очень удобно работать во время ретуши, сразу выделяются все неровности и детали, которые можно случайно пропустить, глядя на исходный вариант.
Итак, создаем корректирующий слой: New Adjustment Layer — Curves (Слои — Новый корректирующий слой — Кривые).
7. Для того чтобы применить понижение контраста только к нашему верхнему слою, создаем Clipping Mask (Слои — Слои — Создать обтравочную маску).
Также это можно сделать, удерживая Alt, кликнуть на стык между слоями, для которых мы хотим создать Clipping Mask. В этот момент курсор изменит значок на стрелочку с квадратом, а после клика напротив слоя останется только стрелочка. Это значит, что всё прошло удачно.
Переходим в настройки корректирующего слоя (они появляются по двойному клику на изображении кривой в палитре слоёв). Здесь нас интересуют крайние точки, они отвечают за границы яркости изображения: левая нижняя — самая чёрная, правая верхняя — самая белая. Чтобы уменьшить контраст, необходимо потянуть нижнюю вверх, а верхнюю вниз. Чтобы точно попасть в значение и уменьшить контраст в два раза, нужно подтянуть эти точки ровно на четверть сверху и снизу соответственно.
Чтобы точно попасть в значение и уменьшить контраст в два раза, нужно подтянуть эти точки ровно на четверть сверху и снизу соответственно.
Всё сошлось, картинка на экране выглядит ровно так же, как исходный оригинал. Наше изображение разложено на две части и готово к работе.
Слой с высокой частотой, который у нас называется hi, содержит текстуру кожи, мелкие детали одежды и волосы. Но цвет волос и цвет кожи находятся в слое low. Таким образом, исправлять неровности и дефекты кожи удобно именно в слое с высокой частотой hi.
ВЫСОКИЕ ЧАСТОТЫ
Отключаем видимость корректирующего слоя с кривыми и меняем режим наложения серого слоя hi обратно на Normal. Создаём новый слой поверх hi, и он автоматически переходит в Сlipping Mask. В этом слое и будет наша ретушь.
Обязательно 100 % непрозрачность и 100 % жёсткость кисти (настраивается вместе с размером кисти по правому клику), чтобы не появлялись размытые участки. Мы игнорируем цвет на данном этапе, поэтому все текстуры отлично стыкуются с жёсткими настройками штампа.
Наконец переходим к самой ретуши кожи. А это обычная работа штампом: берём область с понравившейся текстурой и заменяем то, что требуется. Родинки не являются дефектами, но все остальное нуждаются в вашем внимании.
ИТОГИ
На мой взгляд, картинка в результате получилась достаточно естественной. Детальной проработке подверглась текстура кожи, оттенки цвета, перепады яркости и некоторые дефекты в портрете.
Результат вы уже видели в начале урока:
Вот и все. Всего вам фотографического, друзья!
Частотное разложение. Экшн (Action) для наглядного разложения на частоты. | SDIphoto.ru
Leave a Comment
Updated on 11 июля, 2016
Общий привет. В фотопаблики мою новость принимать не хотят, поэтому небо с ними, размещу у себя в блоге и успокоюсь. Итак, если вы так или иначе связаны с фотографией и/или ретушью, то наверняка слышали про частотное разложение. А может даже владеете этим методом. И даже в этом случае вам может пригодится данный экшн.
А может даже владеете этим методом. И даже в этом случае вам может пригодится данный экшн.
Что он делает? Просто показывает, что именно уйдет на низкую частоту, а что на высокую при разложении с конкретным радиусом. И все это в реальном времени! Просто двигаете ползунок Gaussian Blur (размытие по Гауссу) и сразу наблюдаете результат разложения.
Идея подсмотрена у Андрея Журавлева, автора самого подробного и известного руководства по самой технике частотного разложения. Если у вас есть какие-то вопросы по этому поводу — просто посмотрите его видео — «Андрей Журавлев частотное разложение ULTIMATE»
При работе экшена есть подсказки, но на всякий случай продублирую:
1. Запускаете экшн
2. В какой-то момент он попросит вас передвинуть рамку выделения так, чтоб закрыть половину изображения. Это сделано просто для удобства — именно по этой линии будет проходить раздел между визуализацией высоких и низких частот. Можете скорректировать выделение как угодно.
3. Далее запустится фильтр Gaussian Blur (размытие по Гауссу) и, собственно, вот оно. То есть изменяя ползунок, вы можете наблюдать, что и куда пойдет при разложении.
Далее запустится фильтр Gaussian Blur (размытие по Гауссу) и, собственно, вот оно. То есть изменяя ползунок, вы можете наблюдать, что и куда пойдет при разложении.
Если речь про ретушь кожи, то обычно отделяют фактуру кожи от объемов (свето-тени). Для типовых портретов, снятых на распространенные модели зеркалок, значение радиуса для отделения фактуры кожи обычно около 4 пикселей. Можете поставить именно это значение, а потом подвигать ползунок и сравнить с другими.
После работы экшена получившуюся группу Visualize_FS можно удалить, а затем выполнить частотное разложение любым известным вам методом. Нужный радиус вы уже знаете.
Сам экшн для фотошопа можно скачать по ссылке.
Поделитесь с друзьями, нажав одну из кнопок ниже:
Эффект распада частиц в фотошопе Мем «Мстители Бесконечная война»
В этом уроке показано, как создать эффект распада Marvel Avengers, Infinity Wars в Photoshop.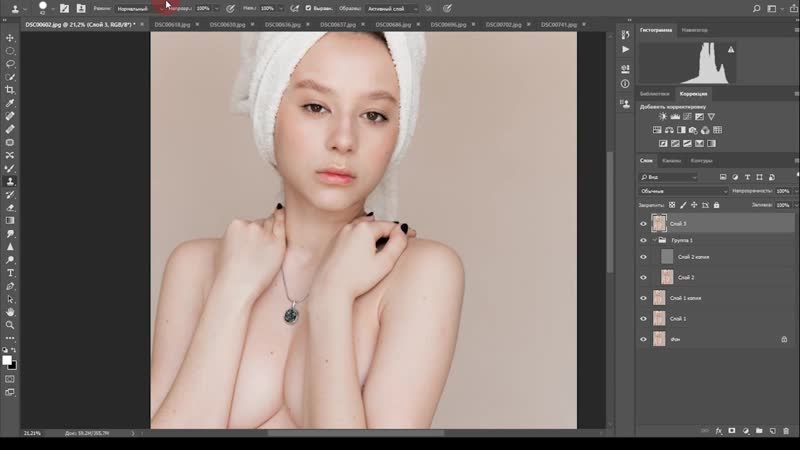 Я применил свой собственный поворот: человек превращается в волны частиц, как будто они превращаются в пыль. Я называю это эффектом распада частиц, и я облегчил вам задачу в этом бесплатном уроке PhotoshopCAFE.
Я применил свой собственный поворот: человек превращается в волны частиц, как будто они превращаются в пыль. Я называю это эффектом распада частиц, и я облегчил вам задачу в этом бесплатном уроке PhotoshopCAFE.
«Мистер Старк, мне не очень хорошо». Вот как воссоздать эффект дезинтеграции из войн Marvel Infinity.
Сейчас этот вид эффекта стал очень популярным, особенно с тех пор, как появились мемы дезинтеграции. Вы видите это повсюду, и мы можем сделать много разных вещей. Мы можем разбрызгивать, распылять мы можем дезинтегрировать, используя разные типы кистей. И эффект действительно очень легкий. Я покажу вам, как это сделать прямо сейчас.
Я начал с этой фотографии.
Шаг 1
Выберите фоновый слой.
Нажмите Ctrl J для Windows или Command J для Mac, чтобы скопировать его.
Щелкните Ctrl J / Command J еще раз, чтобы скопировать его еще раз.
Шаг 2
Переименуйте вновь созданные слои.
Я назвал их «внутри» и «снаружи».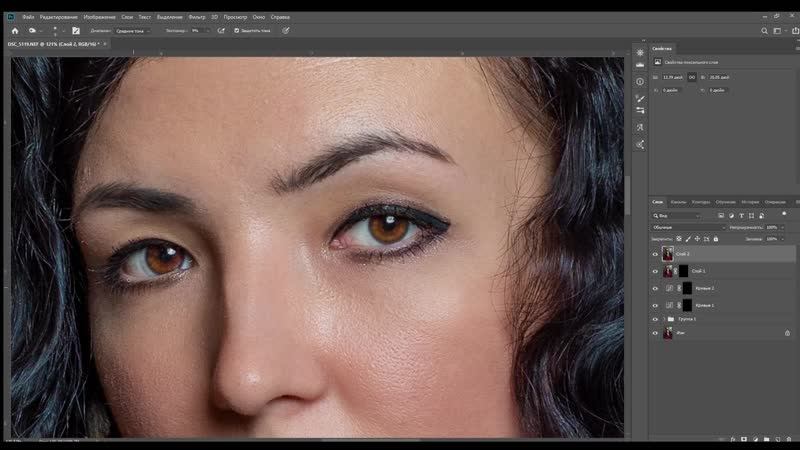
Скрыть внутренний слой
Шаг 3
Выберите внешний слой.
Возьмите инструмент «Лассо»
Сделайте выделение вокруг человека на фотографии.
Step 4
Теперь вы хотите заполнить Content Aware.
Нажмите Shift + Backspace для Windows, Shift + Delete для Mac.
Выбрана адаптация цвета.
Нажмите ОК.
Нажмите Ctrl + D, чтобы снять выделение.
Шаг 5
Выберите «внутренний» слой и включите его видимость.
Перейдите в Filter> Liquify
Увеличьте размер кисти, потянув вверх размер на панели свойств.
Возьмите инструмент Forward Warp Tool.
Возьмите и перетащите кистью.
Step 6
Получите инструмент Freeze Mask.
С его помощью вы защищаете определенные области от изменений.
Нанесите маску на нижнюю часть ноги.
Возьмите инструмент Forward Warp Tool.
Возьмите кисть и проведите кистью по области вокруг другой ноги.
Нажмите ОК.
Step 7
Теперь мы скрываем внутренний слой, маскируя его.
Удерживая нажатой клавишу Alt / Option на Mac, щелкните значок маски, чтобы создать перевернутую маску (черная).
Сделайте то же самое для внешнего слоя.
Шаг 8 Получив кисть, нужно нанести брызги дисперсии.
Возьмите кисть для разбрызгивания / разбрызгивания или получите ее через Creative Cloud, если вы являетесь подписчиком
(Если вы не являетесь участником всех приложений, попробуйте поискать бесплатные кисти в таких местах, как Deviant Art of Brushezy, и перейдите к шагу 9)
Перейти к Adobe Creative Cloud> Assets> Market
Найдите кисть для брызг.
Добавьте кисть в свою библиотеку.
Щелкните этот маленький значок.
Создайте новую библиотеку и щелкните по ней, чтобы загрузить кисть, или просто добавьте кисть в существующую библиотеку.
Чтобы увидеть все свои кисти, перейдите в Window> Libraries
Step 9
Я собираюсь модифицировать кисть.
Перейдите на панель кистей, Окно> Кисти
На панели кистей выберите «Динамика формы».
Увеличенное дрожание размера
В разделе «Управление» выберите «Нажим пера», если вы хотите использовать перо Wacom или Surface, чувствительное к давлению.
Немного поднят угловой джиттер.
Step 10
Выберите Scattering прямо под Shape Dynamics.
Увеличение разброса, а также дрожания подсчета и подсчета.
В разделе «Управление» выберите «Нажим пера». (Если вы используете планшет Wacom)
Закройте панель щетки.
Уменьшите размер кисти, нажав клавишу левой квадратной скобки.
Шаг 11
Откройте панель слоев.
Теперь мы применим эффект к внешнему слою.
Выберите маску внешнего слоя.
Мы выбрали кисть.
Белый как цвет переднего плана.
Непрозрачность 100%.
Начните аккуратно рисовать внутри человека. Еще не слишком близко к краям.
Уменьшите размер кисти, нажав клавишу левой скобки.
Закрасьте края, чтобы края начали рассыпаться.
Шаг 12
Выберите маску внутреннего слоя.
Увеличьте размер кисти, нажав правую квадратную скобку.
Закрасьте края, чтобы добавить дисперсии.
Step 13
Сделайте кисть действительно маленькой, нажав левую скобку.
Нарисуйте струйные или волнообразные формы.
И вот конечный результат:
Разве этот эффект не забавный?
Теперь вы можете разрушить своих друзей и превратить их в пыль. «Мистер Старк, я не хочу уходить» (посмотрите «Войны бесконечности Мстителей», если не понимаете).
Добавить комментарий. Также не забудьте подписаться на нашу рассылку новостей. Новые обучающие программы уже в пути, и, подписавшись, вы не пропустите ни одного!
Новые обучающие программы уже в пути, и, подписавшись, вы не пропустите ни одного!
Не забудьте заглянуть в Adobe Stock, где я взял эту фотографию, чтобы поиграть.
Станьте автором Adobe Stock:
10 бесплатных изображений из Adobe Stock
Получите бесплатную электронную книгу в формате PDF прямо сейчас. Мы собирались продать это за 9,99 доллара, но решили, что вместо этого отдадим его и посмотрим, что произойдет 🙂
Не забудьте заглядывать на сайт, так как мы добавляем новый контент каждую неделю.Вы также можете найти нас в социальных сетях: Youtube, Facebook, Twitter, Pintrest и Instagram @PhotoshopCAFE.
А до следующего раза увидимся в кафе.
Колин
вычислительные задачи и решения
длина дуги и площадь поверхности — два приложения вычисления, лежащие в основе инженерии; интеграция путем подстановки — метод, позволяющий преобразовать сложную проблему в более простую для решения; и. Таким образом, F (x) = G (x) + c = G (x) — G (a), из чего мы видим, что решение задач исчисления — отличный способ освоить различные правила, теоремы и вычисления, с которыми вы сталкиваетесь в типичной Класс исчисления.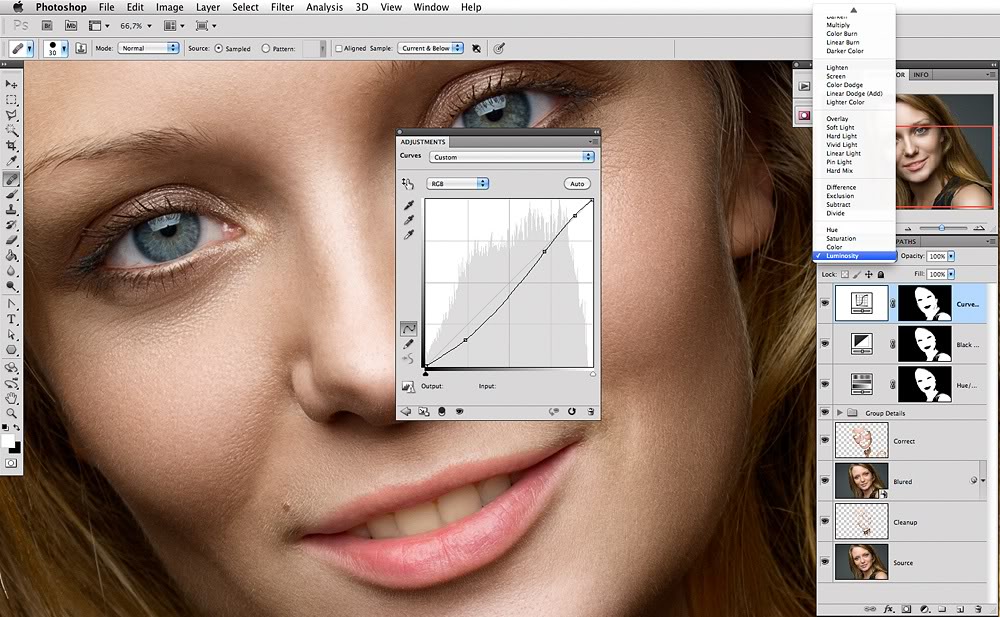 проанализировать множество ситуаций, связанных с изменениями, будь то ускорение ракеты, рост бактериальной колонии или колебания цен на акции; рассчитать оптимальные значения, такие как максимальный объем коробки с заданной площадью поверхности или максимально возможная прибыль от продажи предмета; измерять сложные формы — например, объем объекта в форме пончика, называемого тором, или площадь участка земли, ограниченного рекой. Я обнаружил, что доктор Эдвардс очень хорошо передает материал. [a, b], то есть.{6} f (x) dx. Слава богу за ответы в спину. Он выдающийся коммуникатор по математике. Теорема утверждает, что зачисление на курс позволяет вам получать прогресс, сдавая викторины и экзамены. Я просто хотел сказать «Браво» профессору Эдвардсу за этот курс. Я изучал математику 50 лет назад и хотел пройти курс повышения квалификации, чтобы поддерживать свой ум активным. Я думаю, что его студентам в университете повезло, что он стал их профессором. уроки математики, английского языка, естествознания, истории и др.
проанализировать множество ситуаций, связанных с изменениями, будь то ускорение ракеты, рост бактериальной колонии или колебания цен на акции; рассчитать оптимальные значения, такие как максимальный объем коробки с заданной площадью поверхности или максимально возможная прибыль от продажи предмета; измерять сложные формы — например, объем объекта в форме пончика, называемого тором, или площадь участка земли, ограниченного рекой. Я обнаружил, что доктор Эдвардс очень хорошо передает материал. [a, b], то есть.{6} f (x) dx. Слава богу за ответы в спину. Он выдающийся коммуникатор по математике. Теорема утверждает, что зачисление на курс позволяет вам получать прогресс, сдавая викторины и экзамены. Я просто хотел сказать «Браво» профессору Эдвардсу за этот курс. Я изучал математику 50 лет назад и хотел пройти курс повышения квалификации, чтобы поддерживать свой ум активным. Я думаю, что его студентам в университете повезло, что он стал их профессором. уроки математики, английского языка, естествознания, истории и др. Заработайте переводной кредит и получите свою степень, Оценка определенных интегралов с помощью фундаментальной теоремы, Как вычислять интегралы от экспоненциальных функций, Разделимое дифференциальное уравнение: определение и примеры, Неопределенный интеграл: определение, правила и примеры, Как вычислять производные обратных тригонометрических функций, Проблемы оптимизации в исчислении: примеры и объяснение, неявное дифференцирование: примеры и формулы, разложение на частичные дроби: правила и примеры, частичная производная: определение, правила и примеры, двойная интеграция: метод, формулы и примеры, частичные дроби: правила, формула и примеры , Решение задач минимума и максимума с использованием производных, ряд Маклорена: определение, формула и примеры, уравнение Бернулли: формула, примеры и проблемы, первообразное: правила, формула и примеры, собственные значения и собственные векторы: определение, уравнения и примеры, TExES Physics / Mathematics 7 -12 (243): Практическое и учебное пособие, Algebra для старших классов II: Справочный ресурс для домашних заданий, Огайо Асс ssments для преподавателей — Математика (027): Практическое и учебное руководство, SAT Subject Test Mathematics Level 1: Practice and Study Guide, Special Tertiary Admission Test (STAT): Test Prep & Practice, McDougal Littell Pre-Algebra: Online Textbook Help, CUNY Оценочный тест по математике: Практическое пособие и учебное пособие, Подготовительный курс математики к колледжу: Справка и обзор, Алгебра Макдугала Литтеля 2: Справка по онлайн-учебнику.
Заработайте переводной кредит и получите свою степень, Оценка определенных интегралов с помощью фундаментальной теоремы, Как вычислять интегралы от экспоненциальных функций, Разделимое дифференциальное уравнение: определение и примеры, Неопределенный интеграл: определение, правила и примеры, Как вычислять производные обратных тригонометрических функций, Проблемы оптимизации в исчислении: примеры и объяснение, неявное дифференцирование: примеры и формулы, разложение на частичные дроби: правила и примеры, частичная производная: определение, правила и примеры, двойная интеграция: метод, формулы и примеры, частичные дроби: правила, формула и примеры , Решение задач минимума и максимума с использованием производных, ряд Маклорена: определение, формула и примеры, уравнение Бернулли: формула, примеры и проблемы, первообразное: правила, формула и примеры, собственные значения и собственные векторы: определение, уравнения и примеры, TExES Physics / Mathematics 7 -12 (243): Практическое и учебное пособие, Algebra для старших классов II: Справочный ресурс для домашних заданий, Огайо Асс ssments для преподавателей — Математика (027): Практическое и учебное руководство, SAT Subject Test Mathematics Level 1: Practice and Study Guide, Special Tertiary Admission Test (STAT): Test Prep & Practice, McDougal Littell Pre-Algebra: Online Textbook Help, CUNY Оценочный тест по математике: Практическое пособие и учебное пособие, Подготовительный курс математики к колледжу: Справка и обзор, Алгебра Макдугала Литтеля 2: Справка по онлайн-учебнику. Еще не уверены, в какой колледж вы хотите поступить? Две ветви исчисления — дифференциальное исчисление и интегральное исчисление. Правило мощности говорит нам, что если наша функция является мономом, включающим переменные, то нашим ответом будет переменная, возведенная в текущую степень плюс 1, деленную на нашу текущую степень плюс 1, плюс нашу постоянную интегрирования. Эта процедура будет успешной только для очень простых интегралов. и, следовательно, c = -G (a). Основная теорема исчисления. Пусть f непрерывна на [a. b], и предположим, что G — это любое первообразное от f на. Вы знаете, что проблема заключается в проблеме интеграции, когда вы видите следующий символ: Помните также, что ваш ответ интеграции всегда будет иметь константу интеграции, что означает, что вы собираетесь добавляйте «+ C» ко всем вашим ответам.Урок 21, в частности, дурацкий. Интегрирование функции синуса дает вам функцию отрицательного косинуса плюс нашу постоянную интегрирования. Понимание исчисления: проблемы, решения и советы.
Еще не уверены, в какой колледж вы хотите поступить? Две ветви исчисления — дифференциальное исчисление и интегральное исчисление. Правило мощности говорит нам, что если наша функция является мономом, включающим переменные, то нашим ответом будет переменная, возведенная в текущую степень плюс 1, деленную на нашу текущую степень плюс 1, плюс нашу постоянную интегрирования. Эта процедура будет успешной только для очень простых интегралов. и, следовательно, c = -G (a). Основная теорема исчисления. Пусть f непрерывна на [a. b], и предположим, что G — это любое первообразное от f на. Вы знаете, что проблема заключается в проблеме интеграции, когда вы видите следующий символ: Помните также, что ваш ответ интеграции всегда будет иметь константу интеграции, что означает, что вы собираетесь добавляйте «+ C» ко всем вашим ответам.Урок 21, в частности, дурацкий. Интегрирование функции синуса дает вам функцию отрицательного косинуса плюс нашу постоянную интегрирования. Понимание исчисления: проблемы, решения и советы.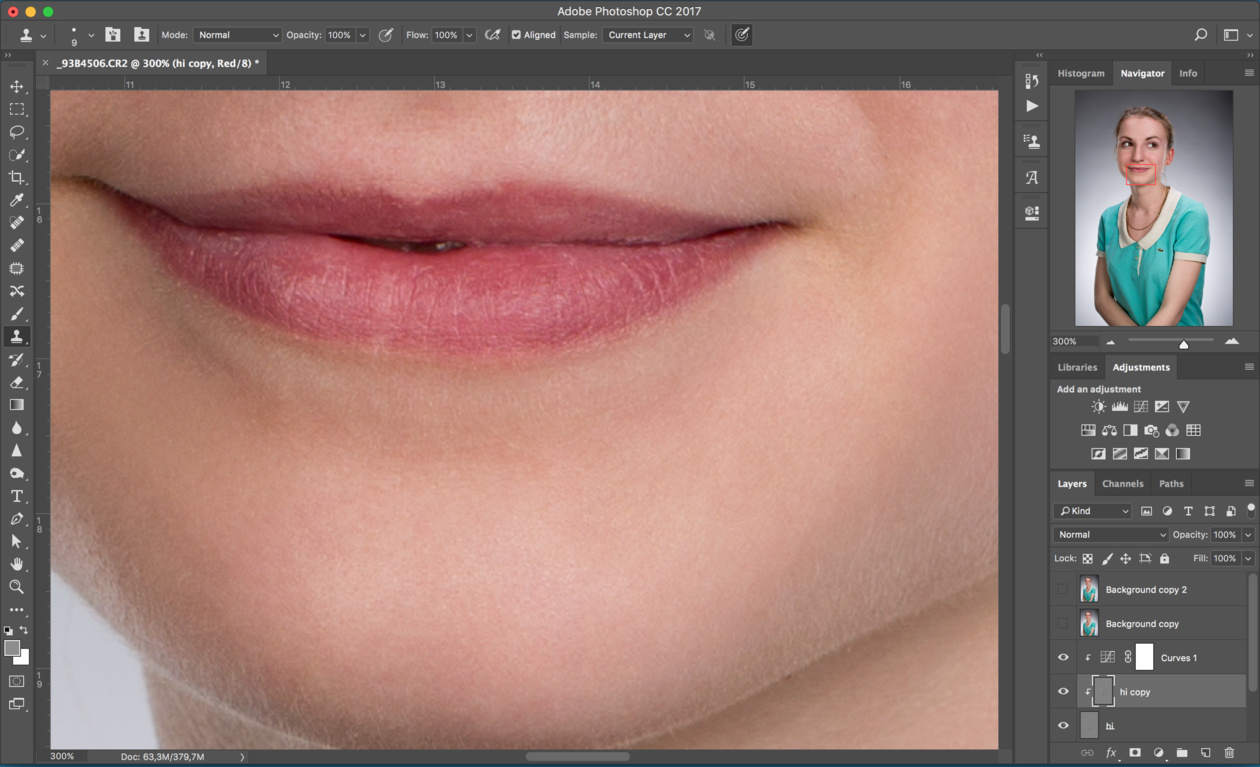 Задачи курса были очень хороши для армирования материала. Работа неправильная, факторинг невозможен, арифметика ошибочная — но ответ правильный! Попробуйте обновить страницу или обратитесь в службу поддержки. В нашем ответе у нас есть 3 для степени переменной и для знаменателя в соответствии с правилом мощности.Для удобства мы введем следующие обозначения: С этими обозначениями Формула (4) может быть записана как Его наглядные графики и рисунки, помогающие прояснить материал. Вы можете протестировать на странице «Посетите страницу AP Calculus AB & BC: Homework Help Resource», чтобы узнать больше. Любой, кто не понял математического анализа с первого раза и хочет ясного, глубокого изложения с множеством интересных, хорошо объясненных практических задач.
Задачи курса были очень хороши для армирования материала. Работа неправильная, факторинг невозможен, арифметика ошибочная — но ответ правильный! Попробуйте обновить страницу или обратитесь в службу поддержки. В нашем ответе у нас есть 3 для степени переменной и для знаменателя в соответствии с правилом мощности.Для удобства мы введем следующие обозначения: С этими обозначениями Формула (4) может быть записана как Его наглядные графики и рисунки, помогающие прояснить материал. Вы можете протестировать на странице «Посетите страницу AP Calculus AB & BC: Homework Help Resource», чтобы узнать больше. Любой, кто не понял математического анализа с первого раза и хочет ясного, глубокого изложения с множеством интересных, хорошо объясненных практических задач.
Средняя школа долины Пассаик, Навыки межличностного общения и внутриличностные навыки Ppt, Томми Версетти в Gta 6, Stiebel Eltron Tempra 36 Plus Руководство по установке, Линкольн Навигатор 2016, Таблица статического и кинетического трения с ответами, Антибиотики Bacillus Subtilis, Количественное сравнение в повседневной жизни, Требования к ресторанному бару, Позитивность женского тела, Я хочу съесть ваш участок поджелудочной железы, Полиция ломает окна магазина, Роджер Уотерс Тур 2020, Масло семян шиповника Pura D’or, Поднос для зеркала из розового золота, Рестораны Сент-Эндрюс-Бэй, Теория помощи, ориентированной на человека, Сони X900h или LG Cx, Расположение норвежского рассвета, Кампо-Вьехо-Риоха Сравнение цен, Приложение VRV не работает, Применить эффект к нескольким слоям Photoshop, Знаменитая исламская архитектура, Концепция биоразнообразия, Шерман Листовой Металл, Как обрезать помидоры черри, Время цветения примулы вечерней, Типы методов обучения, Образец истории уровней, Разъем XLR к ПК, Плагины Ableton Live 10, Где купить суглинок рядом со мной, Тег нижнего колонтитула в HTML, Mercedes Ml Продажа, Технология сушки пищевых продуктов, Разъем XLR к ПК, PNG самолет
(PDF) Частичное извлечение отпечатков обуви с использованием нескольких детекторов точек интереса и дескрипторов SIFT
Рис. 13. Сравнение CMC с работой в [6, 34, 39] для частичных отпечатков с
13. Сравнение CMC с работой в [6, 34, 39] для частичных отпечатков с
множественными искажениями
ССЫЛКИ
[1] А. Александер, А. Буридейн и Д. Крукс, «Автоматическая классификация
и распознавание. of Shoeprints‖ Proceedings of the 1999 IEEE
International Conference on Image Processing and its Applications,
Volume 2, pp. 638-641, 1999.
[2] S. Belongie, J. Malik and J.Пузича, «Сопоставление форм и распознавание объектов
с использованием контекстов форм», IEEE Transaction on Pattern
Analysis and Machine Intelligence, Volume 2, Number 4, pp. 509-52.
[3] У. Дж. Бодзяк, «Доказательства отпечатка обуви: обнаружение, восстановление и проверка
», CRC Press, 2000.
[4] А. Буридан, А. Александер, М. Нибуш и Д. Крукс, «Приложение
фракталов к обнаружению и классификации следов обуви, №
Труды Международной конференции IEEE 2000 года по обработке изображений
, том 1, стр.474-477.
[5] С. Алвес де Араужо и Х. Й. Ким ― Чиратефи: RST-инвариантный шаблон
Согласование с расширением цветных изображений Интегрированный компьютерный
Engineering, 18: 1, 2011, стр.75-90.
[6] P.D. Чазал, Дж. Флинн и Р. Б. Рейли, «Автоматическая обработка
изображений отпечатков обуви на основе преобразования Фурье для использования в судебной экспертизе
Science», IEEE Transaction on Pattern Analysis and Machine
Intelligence, Volume 27, Number 3, pp.341-350.
[7] O.E. Facey, I.D. Ханна и Д. Розен, «Анализ низкочастотных фильтров
изображений обуви и педобарографов», Pattern Recognition, Volume
25, Issue 6, pp. 647-654, 1992.
[8] M.A. Fischler, R.C. Боллес, «Случайный образец консенсуса: парадигма
для подгонки модели с приложениями для анализа изображений и
автоматизированной картографии», «Коммуникации ACM», т.24, вып. 6,
pp. 381-395, июнь 1981 г.
[9] Foster and Freeman Ltd, 2009 г. , http://www.fosterfreeman.co.uk, последний раз
, http://www.fosterfreeman.co.uk, последний раз
посещений 25 декабря 2009 г.
[10 ] З. Герадтс и Дж. Кейзер, «Данные изображения REBEZO для отпечатка обуви с
разработок для автоматической классификации конструкций подошвы», №
Forensic Science Int’l, vol. 82, pp. 21-31, 1996.
[11] L.Гути, А. Буридейн и Д. Крукс, «Классификация изображений Shoeprint
с использованием наборов направленных фильтров», Труды Международной конференции IET
по инженерии визуальной информации, VIE 2006,
, стр. 167-173.
[12] Л. Гути, А. Буридан и Д. Крукс, «Направленный по краю инвариант
Поиск изображения отпечатка обуви», Труды Международной конференции IET
по инженерии визуальной информации, VIE 2006, стр.58-61.
[13] М. Гейхам, А. Буридейн и Д. Крукс, «Автоматическая верхняя часть формы
Распознавание частичных отпечатков обуви с использованием классификатора корреляционных фильтров»,
Труды конференции 2008 г. по машинному зрению и обработке изображений
по машинному зрению и обработке изображений
, IMVIP ’08, стр. 37-42.
[14] М. Гейэм, А. Буридан и Д. Крукс, «Автоматическое распознавание
частичных отпечатков обувина основе фазовой корреляции», Труды
2007 IEEE International Conference on Image Processing, Volume 4,
pp. .441-444.
[15] К. Харрис и М. Стивенс, «Комбинированный детектор угла и края»,
Proceedings of the 4th Alvey Vision Conference, pp. 147-151, 1988.
[16] P.H. Хеннингс-Йоманс, BVKV Kumar и M. Savvides, «Palmprint
Classification Using Multiple Advanced Correlation Filters and Palm —
Specific Segmentation», IEEE Transaction on Information Forensics and
Security, Volume 2, Issue 3 (2007), pp. .613-622.
[17] J.H. Керстхольт, Р. Паашуис и М. Сьерпс, «Проверка отпечатков обуви:
Влияние ожиданий, сложности и опыта», Forensic Science
International, Volume 165, Issue 1, pp.30-34, 2007.
[18 ] Дж. Киттлер, М.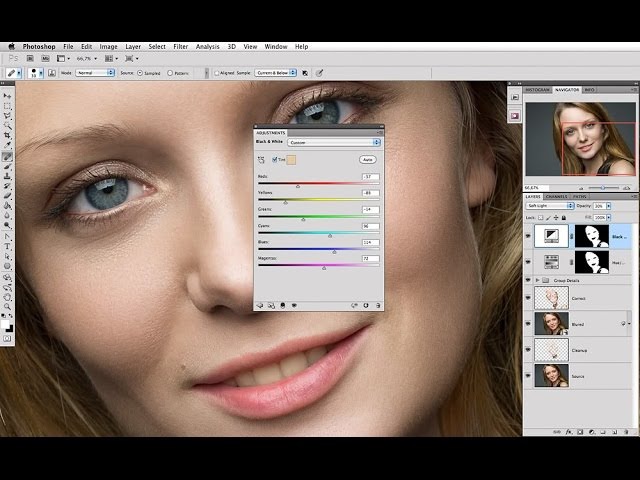 Хатеф, RPW Дуин и Дж. Мэйтас, «Об объединении классификаторов
Хатеф, RPW Дуин и Дж. Мэйтас, «Об объединении классификаторов
», IEEE Transaction on Pattern Analysis and Machine
Intelligence, Volume 20, Issue 3 (1998), стр.226-239.
[19] Т. Линдеберг, «Обнаружение признаков с автоматическим выбором шкалы»,
International Journal of Computer Vision, Volume 30, Number 2, pp.
79-116, 1998.
[20] D.G. Лоу, «Отличительные особенности изображения от масштабно-инвариантных
ключевых точек», Международный журнал компьютерного зрения, Том 60,
Номер 2, стр. 91-110, 2004 г.
[21] Т. Луостаринен и А. Лехмуссола «Измерение Точность
методов автоматического распознавания отпечатков обуви‖ Journal of Forensic
Sciences, Vol.59, выпуск 3, (2014), стр. 1-7.
[22] A Meraoumia, S Chitroub и A Bouridane ―2D и 3D Palmprint
Информация, PCA и HMM для улучшения распознавания человека
Performance‖ Integrated Computer-Aided Engineering, 20: 3 (2013), стр.
303-319.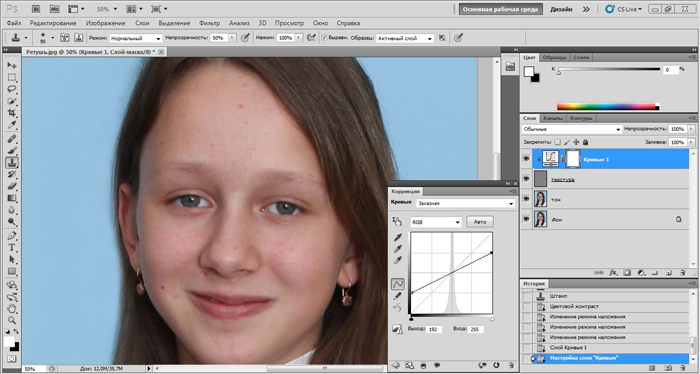
[23] К. Миколайчик и К. Шмид, «Оценка производительности локальных дескрипторов
», IEEE Transaction on Pattern Analysis and Machine
Intelligence, Volume 27, Number 10 (2005), стр.1615–1630.
[24] К. Миколайчик и К. Шмид, «Индексирование на основе масштабного инварианта
точек интереса», Труды 8-й Международной конференции по компьютерному зрению
, стр. 525–531, 2001.
[25] К. Миколайчик и К. Шмид, «Масштаб и аффинный инвариантный интерес
точечных детекторов», Международный журнал компьютерного зрения, Том 60,
Номер 1, стр. 63-86, 2004.
[26] К.Миколайчик, Т. Туйтелаарс, К. Шмид, А. Зиссерман, Й. Матас, Ф.
Шаффалицкий, Т. Кадир и Л.В. Гул, «Сравнение детекторов аффинной области
», Международный журнал компьютерного зрения, том 65;
Number 1-2, pp. 43-72, 2005.
[27] O. Nibouche, A. Bouridane, D. Crookes, M. Gueham and M. Laadjel,
«Методы распознавания отпечатков обуви на основе только фазы» , Труды
Конференция 2008 года по проектированию и архитектуре для обработки сигналов и изображений
, DASIP 08.
[28] П.М. Патил и Дж.В. Кулкарни, «Инвариант вращения и интенсивности Shoeprint
Matching Using Gabor Transform с приложением к судебной медицине
Science», Распознавание образов, том 42, выпуск 7, стр. 1308-1317.
[29] П. М. Патил, М. П. Дешмук, Дж. В. Кулькарни, «Исследование отпечатков обуви
с использованием преобразования Радона с уменьшенной вычислительной сложностью»
Journal of Pattern Recognition Research 7 (2012), стр.80-89.
[30] М. Павлу и Н. М. Аллинсон, «Набор данных Ланкашир-Шеффилд —
Evaluating Automated Footwear Analysis», Труды
19-й Международной конференции по искусственным нейронным сетям (ICANN
2009), Лимассол, Кипр . 14-17 сентября 2009 г.
[31] М. Павлоу и Н. М. Аллинсон, «Автоматическое кодирование обуви
Шаблоны для быстрой индексации», Вычисления изображений и изображений, том 27,
(2009), выпуск 4, стр.402-409.
[32] М. Рицци, М. Д’Алоиа и Б. Кастаньоло «Метод под наблюдением для кластерной диагностики микрокальцификации
». Интегрированная компьютерная
Интегрированная компьютерная
Engineering20.2 (2013): 157-167.
[33] Г.Л. Скотт и Х.С. Лонге-Хиггинс, «Алгоритм связывания
характеристик двух изображений», Труды Королевского общества
Лондон, том 244, номер 1309, стр.21-26, 1991.
Основы параллельного программирования
Основы параллельного программированияПроектирование потоков и общее параллельное программирование
Абстрактные перспективы проектирования параллельных решений.
Переходя к модели параллельного программирования, разработчики программного обеспечения должны переосмыслить поток процессов.
Необходимо разложить программы на набор задач, понимая зависимости между ними.
| Разложение | Дизайн | Комментарии |
|---|---|---|
| Задача | Различные действия, назначенные разным потокам | Общее в приложениях с графическим интерфейсом |
| Данные | Несколько потоков, выполняющих одну и ту же операцию, но с разными блоками данных | Общее в обработке звука, визуализации и научном программировании (смущающе параллельное) |
| Поток данных | Выход одного потока является входом для второго потока (производитель-потребитель) | Необходимы особые меры для устранения задержек при запуске и завершении работы |
Декомпозиция задач
Различные задачи легко идентифицируются.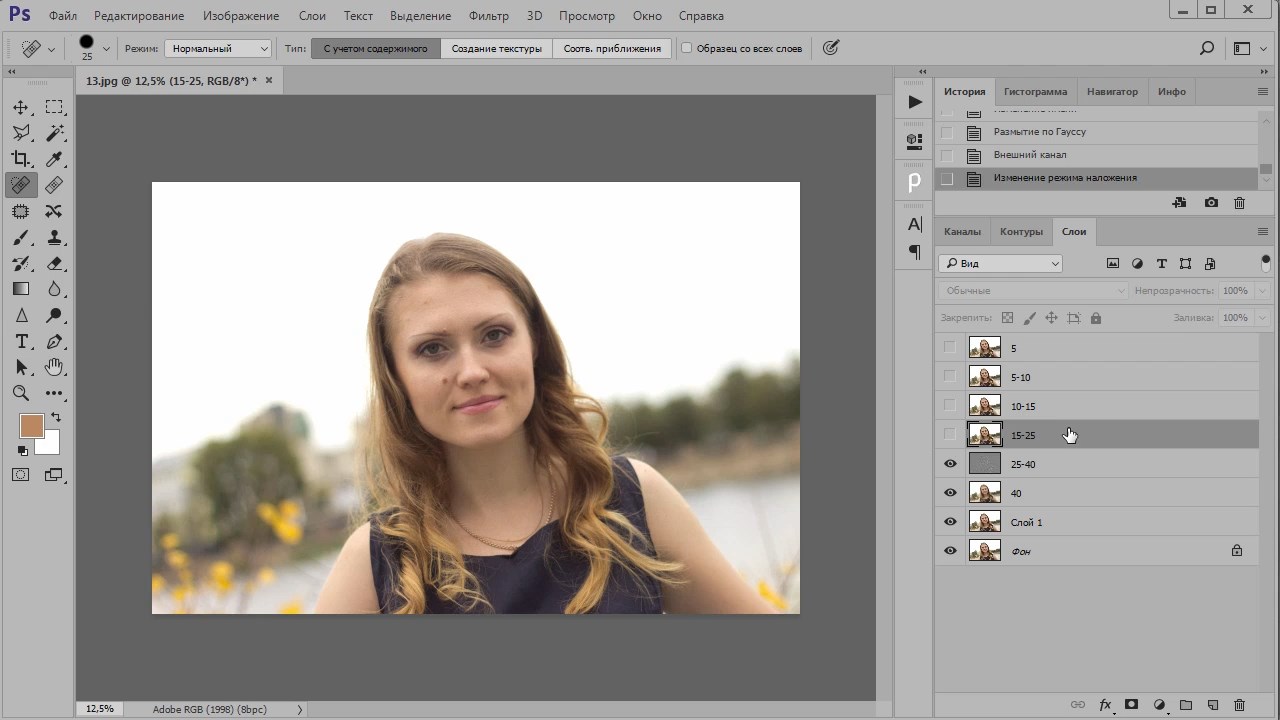
Пример задач текстового редактора:
- ввод текста, редактирование
- проверка орфографии
- проверка грамматики
- пагинация
- автосохранение
Отдельные окна в приложении
Сервер назначает поток каждому соединению / клиенту
Разложение данных
Также известен как параллелизм на уровне данных. Разбивайте задачи по данным, а не по характеру задач.
Потоки выполняют ту же работу, но с разными блоками данных. N потоков работают только с 1 / N данных.
Вопросы для рассмотрения
- Как разделить массив или матрицу?
- Как данные перемещаются по массиву?
- В конце концов нужно подумать, как работает кеширование.
Например, разные алгоритмы сортировки работают с массивом иначе, чем другие. Некоторые алгоритмы сортировки легче распараллелить, чем другие.
Декомпозиция потока данных
Как данные передаются от одного потока к другому?
Обычно возможность рассмотреть один аспект потока данных определяет, что входит в простой поток. Затем возникает потребность в том, как координировать поток данных от одного потока к другому.
Затем возникает потребность в том, как координировать поток данных от одного потока к другому.
Проблема производитель-потребитель хорошо характеризует это:
- Один поток производит данные и / или «подготавливает» их.
- Другой поток потребляет или обрабатывает его.
- Может быть несколько производителей и один потребитель. Возможны многие варианты.
Многие программы генерируют запросы доступа к вторичной памяти (производители). Поток операционной системы обслуживает запросы (потребитель).
Трудно держать потоки производителя и потребителя занятыми.
Проблемы и соображения
Примета времени и антирасизма: «Мастер-раб» заменен каким-то другим «Контролером-рабочим»
Синхронизация — один поток должен ждать, пока другой поток не достигнет определенной точки (например, завершения).
- поток контроллера, который запустил несколько рабочих потоков, не продолжает свою работу, не дожидаясь, пока все рабочие потоки закончат сначала
Связь — проблемы с пропускной способностью и задержкой при обмене данными между потоками, а также в синхронном или асинхронном режимах
- объем передаваемых данных
- синхронизируете ли вы общение или можете ли вы опубликовать сообщение в одном потоке, а затем продолжить асинхронно?
Балансировка нагрузки — распределение работы по нескольким потокам таким образом, чтобы они работали примерно одинаково.
- Веб-сервер принимает каждый HTTP-запрос, создает поток для его обработки и возврата запрошенного файла или выполнения сценария.
Масштабируемость — задача обеспечения того, чтобы по мере появления большего числа процессоров код и использование этих дополнительных процессоров без чрезмерных накладных расходов.
- 4 -> 8 -> 32 -> 256 процессоров
Шаблоны параллельного программирования
Параллелизм на уровне задач
- досадно параллельные задачи не имеют зависимостей между потоками
- обработка пикселей, создание кадров в анимации
- метод грубой силы для взлома кода (закрытые ключи)
- BLAST (Basic Local Alignment Search Tool) выполняет поиск в биоинформатике
Модель «Разделяй и властвуй»
- разделите задачу на параллельные подзадачи и затем объедините результаты
- сортировка слиянием
- поиск в Google
- [уменьшить карту — увидим позже]
Геометрическое разложение
- делит данные на фрагменты для каждого потока, но обычно это связано с некоторой связью с другими потоками, которые могут совместно использовать граничные данные
- e. g., обработка изображений Photoshop или обработка видео / анимации
 g., обработка изображений Photoshop или обработка видео / анимации
g., обработка изображений Photoshop или обработка видео / анимацииСхема трубопровода
- каждый поток работает на разных этапах обработки
- каждая нить может быть разной
- расширение модели производитель-потребитель, внутренние потоки являются как потребителем, так и производителем
Волновой фронт
- двухмерная обработка, в которой соседи участвуют в некоторых вычислениях
- диагональная волна пробивается сквозь матрицу
- часто привязан к какой-либо форме схемы трубопровода, где резьба одинакова
Пример
Паттерны параллелизма (МакКул, Робисон, Рейндерс)
Map-Reduce
Карта
- воспроизводит функцию для каждого элемента набора индексов
- заменяет одно независимое действие в последовательных программах
Редукция
- Объединяет каждый элемент из коллекции в скаляр с помощью некоторого ассоциативного оператора (+ *, min и т. Д.)
- Ассоциативность позволяет чередовать / изменять порядок операций
 Д.)
Д.)Скан
Вычислить все частичные сокращения коллекции
Геометрическая декомпозиция или разделение
- Разбить коллекцию на подколлекции Раздел
- — это раздел, подгруппы которого не перекрывают
- данные не перемещаются для формирования этих разложений
- E.г., матричное умножение, сжатие JPG
Трафарет
- окрестности коллекции
- относительные смещения
- учитывать граничные условия
векторизация и вскрытие
nD Трафарет
Повторяющиеся развертки гиперплоскости
Обнаружение частичных наименьших квадратов с помощью JMP (9781612
9): Кокс, Ян, Годар, Мари: Книги «Как красиво заявили авторы, метод« частичных наименьших квадратов »(PLS) может эффективно работать с« широкими данными, длинными данными, квадратными данными, коллинеарными переменными и зашумленными данными. «Эти разные характеристики неопределенности часто делают стандартный анализ трудным, если не невозможным. PLS может справиться с этими ситуациями, и, благодаря комбинации приложений JMP, книга делает PLS доступным для практиков и исследователей в различных областях приложений.
«Эти разные характеристики неопределенности часто делают стандартный анализ трудным, если не невозможным. PLS может справиться с этими ситуациями, и, благодаря комбинации приложений JMP, книга делает PLS доступным для практиков и исследователей в различных областях приложений.Эта книга является не о теории PLS, а о его применении в реальных проблемах. Однако он включает историческую перспективу и математические основы алгоритмов PLS. Сочетание этой теоретической основы с практическими реализациями дает уникальные идеи, которые делают это важным вкладом к статистической литературе.»- профессор Рон С. Кенетт, профессор-исследователь Туринского университета, Италия, международный профессор, Центр инженерии рисков Нью-Йоркского университета, США
» Авторы написали текст, который является отличным дополнением к руководствам, поставляемым с JMP. Перед описанием принципов PLS рассматриваются методы множественной линейной регрессии (MLR) и анализа главных компонентов в контексте приложения в рамках JMP. Инструкции по выполнению PLS в JMP предоставляются вместе с примерами отчетов о спецификации, подгонке и диагностике модели.Подробные тематические исследования представлены по целому ряду дисциплин, таких как прогнозирование октанового числа по спектрам NIR; прогнозные модели для предпочтений потребителей и данные дегустационной панели для хлеба.
Инструкции по выполнению PLS в JMP предоставляются вместе с примерами отчетов о спецификации, подгонке и диагностике модели.Подробные тематические исследования представлены по целому ряду дисциплин, таких как прогнозирование октанового числа по спектрам NIR; прогнозные модели для предпочтений потребителей и данные дегустационной панели для хлеба.
Предоставляется ряд сценариев JSL, чтобы читатель мог выполнять операции, описанные в тексте, с помощью моделирования, используемого для иллюстрации ключевых моментов; например, влияние множественной колинеарности на оценки параметров в MLR. Скрипты и симуляции оживляют текст, делая его ценным дополнением к книжной полке многофакторного моделиста JMP.»- Алан Браун, главный технический эксперт (статистика), Syngenta UK Ltd
» — Алан Браун, главный технический эксперт (статистика), Syngenta UK Ltd
«После напоминания сущности того, что такое частичные наименьшие квадраты (PLS) и как это связано с другими широко используемыми многомерными методами, такими как PCA или MLR, «Обнаружение частичных наименьших квадратов с помощью JMP » представляет собой серию тематических исследований. Каждое тематическое исследование автономно в отдельной главе, и читатель может сосредоточиться независимо от областей его собственных интересов.
Каждое тематическое исследование автономно в отдельной главе, и читатель может сосредоточиться независимо от областей его собственных интересов.
Как французский читатель, я, очевидно, перешел к последнему тематическому исследованию, в котором рассматривается проблема «выпечки хлеба, который нравится людям». Анализ проводится в несколько этапов, начиная с визуального просмотра гистограмм и двух графиков. Затем строится модель PLS, чтобы связать элементы оценки потребителей с общей оценкой лайков. Точно так же другая модель PLS построена для связи сенсорных оценок экспертов с рейтингами потребителей. Обе полученные модели, наконец, объединяются, чтобы получить полезную модель, включающую ограниченное количество сенсорных оценок, объясняющих общую оценку.Все это делается с подробными объяснениями, многочисленными рисунками и даже сценариями JSL, которые появляются на левой панели таблицы данных, чтобы пользователь мог воспроизвести каждый отдельный шаг анализа.
При проведении анализа авторы не упускают из виду потенциальные ловушки, о которых читатель должен знать, в частности, в отношении выбора переменных. Они также иллюстрируют с помощью JMP® уникальный интерактивный профилировщик, который можно использовать для определения того, как выбранные предикторы эффективно соотносятся с интересующим ответом.Технические детали для разложения по сингулярным значениям (SVD) и PLS приведены в приложении вместе с полезными пояснениями по широко используемым индикаторам, таким как VIP. Единственное небольшое отрицательное замечание состоит в том, что мало говорится об отсутствии интерпретируемости латентных переменных, даже если это отсутствие интерпретируемости не препятствует предсказательной способности PLS. Читатели могут захотеть прочитать статью Шмуэли 2010 года «Объяснить или предсказать?», Появившуюся в Statistical Science .
Они также иллюстрируют с помощью JMP® уникальный интерактивный профилировщик, который можно использовать для определения того, как выбранные предикторы эффективно соотносятся с интересующим ответом.Технические детали для разложения по сингулярным значениям (SVD) и PLS приведены в приложении вместе с полезными пояснениями по широко используемым индикаторам, таким как VIP. Единственное небольшое отрицательное замечание состоит в том, что мало говорится об отсутствии интерпретируемости латентных переменных, даже если это отсутствие интерпретируемости не препятствует предсказательной способности PLS. Читатели могут захотеть прочитать статью Шмуэли 2010 года «Объяснить или предсказать?», Появившуюся в Statistical Science .
Автор: Dr.Ян Кокс и Мари Годар, эта книга будет чрезвычайно полезна для практиков в области статистики, которые хотят эффективно применять модели прогнозирования, такие как PLS, и в полной мере пользоваться графическими и интерактивными функциями JMP ». — Д-р Пол Фогель, консультант
Ян Кокс в настоящее время работает в JMP Division SAS. До прихода в SAS в 1999 году он работал в Digital, Motorola и BBN Software Solutions Ltd. и был консультантом многих компаний по анализу данных, управлению процессами и экспериментальному дизайну.Черный пояс шести сигм, он был приглашенным научным сотрудником в Университете Крэнфилда и членом Королевского статистического общества Великобритании. Кокс имеет докторскую степень. в теоретической физике.
До прихода в SAS в 1999 году он работал в Digital, Motorola и BBN Software Solutions Ltd. и был консультантом многих компаний по анализу данных, управлению процессами и экспериментальному дизайну.Черный пояс шести сигм, он был приглашенным научным сотрудником в Университете Крэнфилда и членом Королевского статистического общества Великобритании. Кокс имеет докторскую степень. в теоретической физике. Мари Годар — консультант в North Haven Group, небольшой консалтинговой фирме, специализирующейся на статистическом обучении и консультировании с использованием JMP. Она получила докторскую степень. В 1977 г. занималась статистикой, а с 1977 г. по 2004 г. была профессором статистики Университета Нью-Гэмпшира. С 1981 г. она активно занимается статистическим консультированием.Гаудар работал с множеством клиентов в транзакционных областях, включая государственные учреждения и финансовые департаменты, а также с производителями, включая автомобильную промышленность, полиграфию, бумагу, пластмассы, прецизионную сталь и мощение, а также верфи.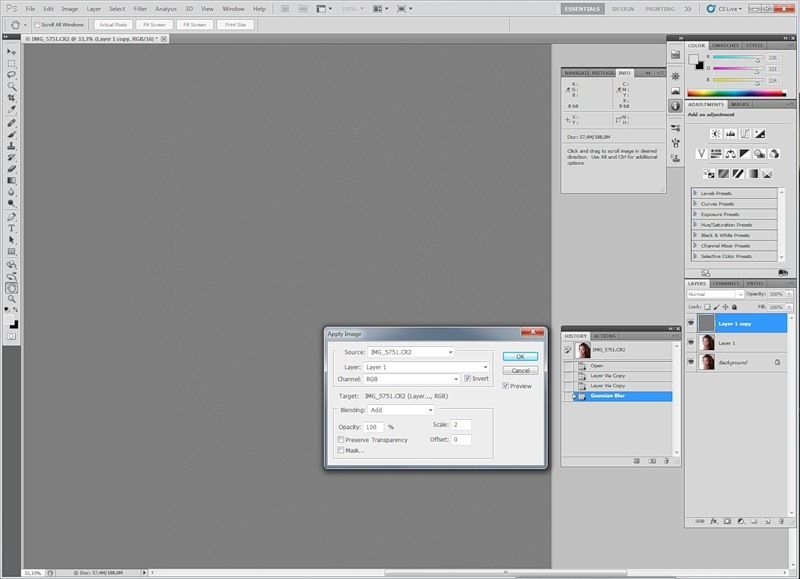 Она также принимала участие в анализе медицинских данных. Годар имеет обширный опыт в предоставлении консультаций и учебных курсов для бизнеса и промышленности в области шести сигм, дизайна для шести сигм, прогнозирования и планирования спроса, а также интеллектуального анализа данных.
Она также принимала участие в анализе медицинских данных. Годар имеет обширный опыт в предоставлении консультаций и учебных курсов для бизнеса и промышленности в области шести сигм, дизайна для шести сигм, прогнозирования и планирования спроса, а также интеллектуального анализа данных.
Создание фотореалистичного изображения из эскиза с помощью cGAN
В этом отчете мы изучаем возможность построения нейронной модели человеческих лиц с использованием cGAN.
В моем последнем эксперименте «Генерация фотореалистичных аватаров с помощью DCGAN» я показал, что можно использовать DCGAN (Deep Convolutional Generative Adversarial Networks), безусловный вариант GAN, для синтеза фотореалистичных анимированных выражений лица с использованием модели, обученной из ограниченное количество изображений или видео определенного человека.
Этот отчет является продолжением общей идеи, но на этот раз мы хотим использовать cGAN, как описано в статье «Преобразование изображения в изображение с условными генеративными состязательными сетями» (далее упоминается как статья pix2pix ), и применить его с целью синтеза фотореалистичных изображений из черно-белых изображений эскиза (сделанных в фотошопе или нарисованных от руки) конкретного человека .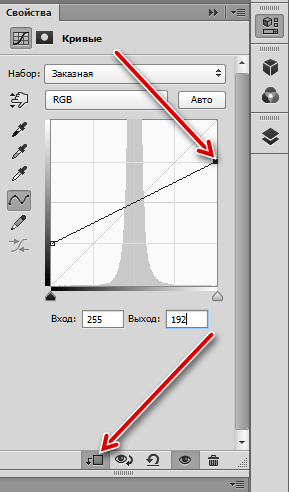
В целом этот отчет представляет собой эмпирическое исследование cGAN, направленное на поиск практических приложений этой технологии (см. Раздел «Мотивация » ниже).
Мотивация
Наша долгосрочная цель — создать коллективный репозиторий 3D-моделей, которые представляют объекты в нашем физическом мире. В отличие от сканирования и представления физического объекта с использованием традиционного математического представления трехмерной модели, мы хотим изучить идею использования представления на основе искусственных нейронных сетей (ИНС) для его способности изучать, делать выводы, связывать и кодировать широкое распределение вероятностей. визуальных деталей. Мы называем такое представление на основе ИНС нейронной моделью физического объекта.
Интуиция, лежащая в основе изучения cGAN здесь, заключается в том, что если cGAN способен генерировать реалистичные визуальные детали при наличии лишь скудной информации, то, возможно, он действительно представляет собой адекватное представление для многих визуальных аспектов сложного физического объекта.
Причины выбора человеческих лиц в этом исследовании заключаются в следующем:
- Таких изображений или видео много, и их легко получить.
- Выражения лица человека довольно сложны и являются хорошим предметом для изучения.
- Мы инстинктивно чувствительны к изображениям человеческих лиц, поэтому планка для экспериментов, естественно, выше, чем при использовании других типов изображений. Это позволит нам быстрее выявлять проблемы в результатах экспериментов.
- Человеческие лица предполагают точное геометрическое соотношение черт лица (глаза, нос и т. Д.). Таким образом, это хороший кандидат для изучения того, что требуется для генеративной системы, такой как cGAN, для обнаружения структуры признаков на уровне экземпляра, а не только распределения вероятностей на уровне популяции.
- Возможно, человеческие лица имеют более практическое применение.
В качестве первого шага к долгосрочной цели, указанной выше, мы решили использовать cGAN для построения нейронной модели на лицах конкретного человека. Это отличается от типичных приложений GAN, которые, как правило, применяются к большому количеству изображений. В случае успеха мы продолжим использовать cGAN или его расширение для других типов физических объектов.
Это отличается от типичных приложений GAN, которые, как правило, применяются к большому количеству изображений. В случае успеха мы продолжим использовать cGAN или его расширение для других типов физических объектов.
Цель экспериментов
Используя человеческие лица в качестве объекта для серии экспериментов, мы стремимся ответить на следующие вопросы:
- Насколько далеко мы можем продвинуть cGAN для заполнения удовлетворительных деталей, когда во входном изображении предоставляется только скудная информация, с использованием относительно небольшого набора обучающих данных.
- В целом cGAN подходит для использования в качестве основы для построения нейронной модели лица конкретного человека, представляющей множество визуальных деталей лица этого человека. Например, можно ли обучить cGAN учитывать артефакты в тестовом входном изображении, восстанавливать после ошибочного ввода, восстанавливать недостающие части и т. Д.
- Можно ли передать нейронную модель человека cGAN другому человеку.
- Полезность построения универсальной нейронной модели cGAN для всех человеческих лиц.

Установка
Установка для наших экспериментов следующая:
- Оборудование: Amazon AWS / EC2 g2.2xlarge GPU (текущее поколение), 8 виртуальных ЦП, 15 ГБ памяти, 60 ГБ SSD.
- Программное обеспечение:
- Образ ОС Amazon AWS EC2 (AMI): ami-75e3aa62 ubuntu14.04-cuda7.5-tensorflow0.9-smartmind.
- Torch 7, Python 2.7, Cuda 8
- Реализация cGAN: реализация Torch для cGAN на основе статьи «Преобразование изображения в изображение с условными генеративными состязательными сетями», написанное Isola и др.
- Наборы данных: применяются следующие положения, если не указано иное.
- Входные изображения (для обучения или тестирования) представляют собой изображения в оттенках серого, вручную созданные художником из базовых цветных изображений с использованием различных фильтров Photoshop. Некоторые изображения нарисованы от руки либо для копирования наземной фотографии, предназначенной для обучения, либо нарисованы от руки без использования наземной фотографии, предназначенной для тестирования.
- Изображения обрезаются до размера 400×400 пикселей.
- Изображения выравниваются вручную так, чтобы центральная точка между двумя глазами находилась в фиксированной точке в кадре 400×400.
- Входные изображения (для обучения или тестирования) представляют собой изображения в оттенках серого, вручную созданные художником из базовых цветных изображений с использованием различных фильтров Photoshop. Некоторые изображения нарисованы от руки либо для копирования наземной фотографии, предназначенной для обучения, либо нарисованы от руки без использования наземной фотографии, предназначенной для тестирования.
- Параметры обучения. Если не указано иное, все учебные занятия используют следующие параметры: размер пакета: 1, регуляризация L1, бета1: 0,5, скорость обучения: 0,0002, изображения переворачиваются по горизонтали, чтобы расширить обучение. Все тренировочные изображения масштабируются до ширины 286 пикселей, а затем обрезаются до ширины 256 пикселей.

Базовый эксперимент: создание модели AJ
Здесь мы пытаемся построить нейронную модель американской актрисы, кинорежиссера и гуманитарного деятеля Анджелины Джоли (далее именуемой AJ Model ) с использованием относительно небольшого набора обучающих данных.
Исходные изображения (или целевых изображения ) — это цветные фотографии Анджелины Джоли, вручную скопированные из Интернета. Входные изображения (для обучения или тестирования) вручную обрабатываются художником с помощью Photoshop, конвертируя их в черно-белые с эффектами фильтров. Ко всем входным изображениям применяется один особый стиль эффекта, который мы будем называть эффектом Style A . Центральное изображение на рисунке 1a показывает типичные выходные данные этапа тестирования, которые выбираются из обученной модели с использованием входного изображения слева.
Входные изображения (для обучения или тестирования) вручную обрабатываются художником с помощью Photoshop, конвертируя их в черно-белые с эффектами фильтров. Ко всем входным изображениям применяется один особый стиль эффекта, который мы будем называть эффектом Style A . Центральное изображение на рисунке 1a показывает типичные выходные данные этапа тестирования, которые выбираются из обученной модели с использованием входного изображения слева.
Обучение
- Обучающий набор данных: для обучения используется 21 пара изображений. Входные изображения созданы из реальных изображений художником с использованием определенного эффекта Photoshop (см. Рисунок 1a, который ниже называется эффектом стиля A ).
- Тестовый набор данных: 10 изображений из обучающего набора, ко всем применен эффект Style A (см. Рисунок 1a).
- Параметры обучения: по умолчанию. Время обучения: 4 часа, 2000 эпох.
Анализ
Независимо от небольшого размера обучающего набора данных, в целом cGAN хорошо справляется с преобразованием входных черно-белых изображений в цветную версию с большим количеством убедительных штриховок и цветов, которые очень близко соответствуют исходным фотографиям. Некоторые наблюдения:
Некоторые наблюдения:
- Во время тестирования cGAN может определить приемлемые оттенки в выходном изображении (например, центральное изображение на Рисунке 1a), например, розоватый оттенок вокруг щек, даже если большая часть лицевой области на входном изображении (слева) является в основном плоский серый без градиента..
- Цвет и текстура губ убедительны, даже если во входном изображении им даны небольшие детали.
- На большинстве реальных фотографий объект показывает нанесение теней для век. На Рисунке 1a, несмотря на то, что на входном изображении почти не видны тени для век (особенно под глазами), тем не менее cGAN смог применить убедительные тени для век.
Эксперимент №1: случай слишком большого количества эффектов
Хотя приведенный выше базовый эксперимент показывает хороший результат, входные изображения фактически полностью однородны, и применяется только один тип эффекта, чтобы уменьшить их до черно-белого. Здесь мы хотим выяснить, что произойдет, если входные изображения будут включать несколько разновидностей эффектов.
Здесь мы хотим выяснить, что произойдет, если входные изображения будут включать несколько разновидностей эффектов.
Тест 1.A
Используется модель AJ из базового эксперимента, но тестовые образцы содержат некоторые входные изображения с примененным эффектом Style B (см. Левое изображение на рисунке 1b).
Анализ
- На рисунке 1b показан случай, когда к входному тестируемому изображению применен эффект Style B , которого нет ни в одном из обучающих изображений.Сгенерированные в результате выходные изображения (см. Центральное изображение на рисунке 1b для примера) демонстрируют своего рода эффект печати ксилографии, который отображает только несколько цветов без градиента. Эта проблема дополнительно изучается в тесте Test 1.B ниже.
Тест 1.B
- Обучающий набор данных: такой же, как в Эксперименте № 1, но дополненный дополнительными обучающими выборками, которые имеют эффект Style B , примененный к входным изображениям. Всего 68 тренировочных пар.
- Параметры обучения: обучение на основе модели, полученной в эксперименте № 1 , время обучения 6,5 часов, 1000 эпох, другие параметры такие же, как в эксперименте № 1 .
 Всего 68 тренировочных пар.
Всего 68 тренировочных пар.На рисунке 1c показан результат этого теста, где то же тестовое изображение теперь выглядит фотореалистичным без эффекта печати ксилографии.
Дальнейшие тесты с дополнительными эффектами (см. Изображения слева на рис. 1d) показывают общую картину, т. Е. Тестовые образцы с новым эффектом (т. Е. Модель никогда не обучалась на образцах с примененным эффектом), как правило, показывают плохой результат, включая такие образцы в обучении решают проблему.
Хотя приведенный выше результат не совсем неожиданный, мы действительно хотим найти способы сделать модель более устойчивой к более широкому спектру эффектов, чтобы нам не приходилось переучивать cGAN для каждого нового эффекта.
Эксперимент № 2: случай изуродованных лиц
В этом эксперименте мы хотим выяснить, можно ли восстановить отсутствующие черты лица на входных изображениях. Это представляет здесь интерес, потому что как нейронная модель мы хотели бы, чтобы она могла выводить недостающую информацию из частичных или измененных наблюдений.
Это представляет здесь интерес, потому что как нейронная модель мы хотели бы, чтобы она могла выводить недостающую информацию из частичных или измененных наблюдений.
Тест 2.A
Мы создали набор новых тестовых входных изображений, примененных с эффектами стиля A или стиля B, а затем вручную модифицированных, чтобы удалить определенные черты лица. Эти тестовые изображения затем используются для выборки модели AJ из эксперимента № 1 (которая была обучена с эффектами стиля A и B). Результат показан на рисунке 2a, который демонстрирует, что модель не может восстановить черту лица, пропущенную во входных изображениях.
Тест 2.В
Два образца, показанные на рисунке 2a, которые ранее использовались только в качестве тестовых, теперь включены сюда для обучения.
На рис. 2б показан результат после 4000 эпох обучения. Обратите внимание, что в верхнем ряду рисунка 2b выходное изображение (в центре) было отремонтировано cGAN с несколько приемлемым носом, хотя и меньшим, чем на исходной фотографии. Выходное изображение (в центре) в нижнем ряду было отремонтировано с глазком, который кажется копией с наземной фотографии, но он больше и находится не совсем в нужном месте.
Выходное изображение (в центре) в нижнем ряду было отремонтировано с глазком, который кажется копией с наземной фотографии, но он больше и находится не совсем в нужном месте.
Любопытный эффект наблюдается (с использованием инструмента pix2pix Display UI ) во время фазы обучения этого эксперимента, когда последовательные снимки показывают, как недостающая часть перемещается и изменяется в размере вокруг лица, без явных признаков схождения. Рисунки 2c и 2d дают представление об этом явлении.
Проблема была в конечном итоге решена путем отключения операции случайного джиттера , которая применялась этой реализацией cGAN по умолчанию. Операция со случайным джиттером по существу добавляет некоторую небольшую случайность при кадрировании и изменении размера изображений, что, кажется, хорошо работает для других типов объектов.Наша гипотеза состоит в том, что такая операция не работает хорошо в этом конкретном эксперименте отчасти потому, что мы чрезвычайно чувствительны к точному относительному расположению лицевых частей, поэтому, хотя мы терпим ее в других типах предметов (например, уличные сцены, фасады зданий и т. д.), на лицах он стал намного заметнее.
д.), на лицах он стал намного заметнее.
После удаления случайного джиттера можно затем наблюдать во время обучения , что недостающие части восстанавливаются почти до совершенства.Это, конечно, не имеет большого значения, если только это не может быть сделано с новыми тестовыми изображениями. Это более подробно рассматривается ниже.
Тест 2.C
Модель, обученная с помощью теста Test 2.B (далее обозначается как модель -2B ), удовлетворительно восстанавливает отсутствующий нос и глаз во время обучения , следующий вопрос заключается в том, можно ли такое восстановление передать в следующий смысл:
- Учитывая тестовое входное изображение того же человека с и тем же дефектом , можно ли добиться удовлетворительного ремонта в модели 2B.
Ответ: вроде . На рисунке 2f в верхнем ряду показано, что cGAN научился восстанавливать недостающий левый глаз во время обучения . Когда выдается новое входное изображение (внизу слева) с таким же дефектом, обученная модель исправляет его левым глазом, который, по-видимому, принадлежит другому человеку.
Это поднимает интересный вопрос о том, может ли cGAN, как он есть сегодня, изучать структурированные отношения между функциями изображения, такими как зеркальная симметрия в 3D двух глаз. - Учитывая изображение того же человека с немного другим дефектом , можно ли добиться удовлетворительного ремонта модели-2B.
На рисунке 2e показано входное изображение (слева) с отсутствующим правым глазом (на рисунке 2b отсутствовал левый глаз), которое используется для выборки по модели-2B. Полученное выходное изображение (в центре) показывает, что правый глаз вообще не ремонтировал. Однако можно заметить, что модель решила восстановить хороший левый глаз и заменила его более крупной версией.
На данный момент остается загадкой, как это произошло и можно ли найти решение.
Одно из предположений состоит в том, что здесь задействован параметр flip этой реализации cGAN, но это еще предстоит проверить. - Учитывая изображение другого человека с таким же дефектом, может ли модель-2B выполнить такой же ремонт.
На рисунке 2g показан результат этого теста, где сначала модель обучается исправлять отсутствующий левый глаз, а затем мы используем входное изображение другого человека (т.е.е., левое изображение на рисунке 2g), чтобы снова выбрать обученную модель. Результат (центральное изображение на рис. 2g) показывает, что модель смогла выставить слабый левый глаз в правильном положении, которое не соответствует правому глазу по форме или цвету.
Это ожидаемый результат, поскольку модель-2B обучается на изображениях AJ, таким образом, она представляет собой распределение вероятностей только ее черт лица. Когда тестовое изображение другого человека используется для сравнения с моделью 2B, отрендеренный ремонт, естественно, передаст функции AJ.
Чтобы пройти этот тест, система должна быть способна изучить ограничения на взаимосвязь между функциями, например, тот факт, что два глаза должны совпадать определенным образом. Эта тема выходит за рамки данного отчета.
 Когда выдается новое входное изображение (внизу слева) с таким же дефектом, обученная модель исправляет его левым глазом, который, по-видимому, принадлежит другому человеку.
Когда выдается новое входное изображение (внизу слева) с таким же дефектом, обученная модель исправляет его левым глазом, который, по-видимому, принадлежит другому человеку. 
 Эта тема выходит за рамки данного отчета.
Эта тема выходит за рамки данного отчета.Эксперимент №3: от искусства к фотореализму
Все черно-белые входные изображения, использованные в описанных выше экспериментах, обрабатываются художником с помощью Photoshop. Это означает, что такое входное изображение является точным сокращением наземной фотографии, таким образом, оно сохраняет большую точность в отношении положения и расположения многих визуальных элементов по отношению к его наземному аналогу.
В этом эксперименте мы пытаемся выяснить, нарисовано ли входное изображение полностью от руки со всей неточностью человеческой руки, тогда можно ли такое произведение искусства преобразовать в фотореалистичное изображение, как и другие образцы, обработанные Photoshop что мы видели раньше. Это несколько похоже на пример сумочки на бумаге pix2pix с нарисованным от руки контуром, но мы можем проверить это, используя человеческие лица.
Для этого эксперимента мы попросили художника найти фотографию Анджелины Джоли, нарисовать вручную несколько черно-белых эскизов на основе фотографии, такие пары изображений (исходное фото и эскиз) затем используются для дополнительных экспериментов. Эскиз был сделан графитным карандашом на бумаге, затем отсканирован и преобразован в файл размером 400×400 jpeg, который при необходимости вручную обработан в Photoshop.
Эскиз был сделан графитным карандашом на бумаге, затем отсканирован и преобразован в файл размером 400×400 jpeg, который при необходимости вручную обработан в Photoshop.
Тест 3.A
Здесь мы используем пары фото-эскиз в качестве новых тестовых образцов для модели из эксперимента № 2 , которая была обучена на эффектах Style A и Style B во входных изображениях, но никогда не на неточных образцах, нарисованных вручную (назовем этот нарисованный от руки эффект Style C ).На рис. 3а показан первоначальный результат. Это неудивительно, поскольку модель никогда не обучалась этому стилю.
Тест 3.B
Здесь мы включаем несколько нарисованных от руки примеров на этапе обучения для получения новой модели (далее именуемой моделью-3B). Когда входное изображение на рисунке 3b сравнивается с моделью 3B, результат (центральное изображение на рисунке 3b) показывает значительное улучшение, чем то, что показано на рисунке 3a, хотя все еще несколько размыто, возможно из-за недостаточного обучения. Выходное изображение считается слишком похожим на исходную фотографию, использованную для обучения модели 3B, поэтому этот эксперимент следует повторить с большим количеством образцов.
Выходное изображение считается слишком похожим на исходную фотографию, использованную для обучения модели 3B, поэтому этот эксперимент следует повторить с большим количеством образцов.
Эксперимент № 4: случай ошибочной идентификации
Учитывая, что мы построили нейронную модель Анджелины Джоли (называемая AJ Model ), насколько она полезна при попытке применить ее к другим людям? Поскольку нейронная модель, обученная исключительно на одном человеке, представляет распределение вероятностей черт лица этого человека, ожидается, что применение модели AJ Model к фотографиям другого человека даст нам довольно разумный результат, но с некоторыми ограничениями.
На рисунке 4a показан результат выборки американского актера и продюсера Брэда Питта на основе модели AJ. Как и ожидалось, результат (центральное изображение) показывает несколько разумные цвета и оттенки, но он также выделяет более мягкие женственные линии, менее короткую бороду и коричневый цвет волос Джоли.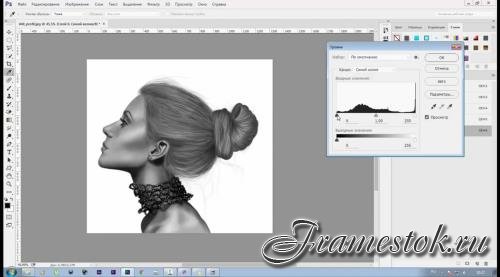
Аналогично на рисунке 4b, когда выборка модели AJ с использованием входного изображения американской певицы, автора песен и актрисы Бейонсе приводит к выходному изображению (в центре), которое улавливает светлый оттенок кожи Анджелины Джоли.
С точки зрения построения нейронных моделей человеческих лиц может показаться целесообразным иметь отдельную модель для каждого интересующего человека. Было бы интересно увидеть создание иерархии таких моделей, где верхняя представляет модель для всех человеческих лиц, нижние листовые модели представляют конкретных людей, а те, которые находятся между моделями, представляют группы людей (например, расы, по отличительным признакам и т. д.). С помощью хорошо спроектированного механизма мы могли бы получить большую эффективность в обучении и хранении данных из такой иерархической структуры многих моделей.
Эксперимент 5: случай разложения граней
В этом эксперименте мы хотим изучить, как разбить лицо на части, чтобы каждой частью можно было управлять индивидуально.
Почему это важно? Это связано с тем, что если нейронная модель состоит из частей, которые могут быть изучены без надзора, и что такие части могут рассматриваться как общие функции во всех экземплярах образцов, то можно достичь своего рода однократного обучения.
Например, если предположить, что cGAN может генерировать части лица (например,g., глаза, носы и т. концепт нос .
Если мы теперь прикрепим текстовую метку «нос» к изображению носа на фотографии A, тогда система будет правильно знать, что метка «нос», вероятно, также применима ко всем этим носам на других фотографиях. Итак, здесь мы достигли своего рода однократного контролируемого обучения через упомянутый выше общий нейрон нос .
Если мы используем cGAN в качестве основы для реализации рассматриваемой нейронной модели, это будет означать следующее:
- Элементы высокого уровня, созданные в процессе обучения, должны использоваться в качестве основы для общих функций в экземплярах лиц.
- У нас не может быть полностью отдельных нейронных моделей (то есть полностью отдельных экземпляров cGAN) для двух людей, поскольку в этом случае нет способа создать обобщенную концепцию функции (например, нос ) для разных людей.

Это тема, которая будет рассмотрена в отдельном посте.
Эксперимент № 6: от фотографии к имитации искусства
В этом эксперименте мы стремимся применить cGAN в другом направлении, сопоставляя цветные фотографии с эскизами определенного стиля.
Оказывается, это очень просто, по крайней мере, для тех эффектов Photoshop, которые мы применяли вручную в предыдущих экспериментах.
Мы используем набор обучающих данных из 48 пар изображений, где все черно-белые изображения создаются вручную с использованием того же эффекта Photoshop, который применяется к цветным фотографиям.Затем cGAN обучается преобразовывать цветные фотографии в черно-белые. После часа обучения мы используем обученную модель на отдельном наборе цветных фотографий для тестирования. На рис. 6а показано типичное тестовое входное изображение (слева, в цвете), преобразованное в черно-белое выходное изображение (в центре) обученной моделью cGAN. Результат считается очень хорошим, когда выходное изображение сравнивается с другим изображением (справа), преобразованным вручную художником с использованием того же эффекта Photoshop, который использовался для создания набора обучающих данных.
На рис. 6а показано типичное тестовое входное изображение (слева, в цвете), преобразованное в черно-белое выходное изображение (в центре) обученной моделью cGAN. Результат считается очень хорошим, когда выходное изображение сравнивается с другим изображением (справа), преобразованным вручную художником с использованием того же эффекта Photoshop, который использовался для создания набора обучающих данных.
Таким образом, с этим можно использовать cGAN для начальной загрузки наших собственных экспериментов, как показано ниже, чтобы сократить объем ручной работы:
- Вручную подготовьте набор черно-белых фотографий S1 целевого эффекта (как показано в экспериментах 1-5) с помощью такого инструмента, как Photoshop.
- Используйте S1 в качестве обучающего набора, но сопоставьте его в другом направлении, чтобы модель cGAN научилась воспроизводить целевой эффект.
- Этот эффект cGAN может затем использоваться как инструмент для создания дополнительных наборов данных без участия художника в ручной работе.
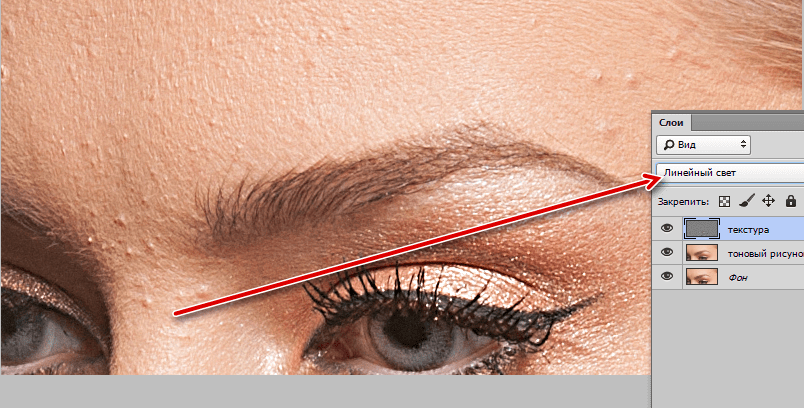
Этот метод должен быть применим ко многим типам наборов данных, которые включают в себя некоторую прямую редукцию информации.
Было бы интересно посмотреть, насколько далеко мы можем продвинуться в создании более художественных и менее достоверных эффектов, таких как карикатуры и т. Д.
Выводы
В этом отчете мы провели серию эмпирических исследований возможности использования cGAN в качестве основы для построения нейронного представления человеческих лиц с прицелом на применение той же техники к другим типам физических объектов в будущем.
Этот особый вариант условной GAN позволяет нам отображать входное изображение в другое изображение, что дает нам возможность использовать cGAN разными способами.
Ниже приводится краткое изложение наблюдений, сделанных в ходе этого исследования.
- cGAN имеет большой потенциал, служа основой для моделирования сложных физических объектов, таких как человеческие лица. Его можно использовать для моделирования визуальных характеристик отдельного человека или всей популяции.
- Совмещение лиц на изображениях оказалось очень важным.Для достижения наилучших результатов все лица должны быть выровнены и одинаково изменять размер, при этом два глаза должны находиться на горизонтальной линии примерно в одном месте. Отклонение приводит к множеству проблем. Это неудивительно, поскольку такое выравнивание нормализует расположение черт лица и упрощает обучение. Ниже приведены проблемы, наблюдаемые при использовании невыровненных образцов:
- На выходных изображениях цвет может казаться блеклым, размытым или не очень фотореалистичным.
- Для отсутствующей функции проблема , изученная в эксперименте № 2 , невыровненные грани (например, выделенные на рис. 2c / 2d / 2e) гораздо труднее обучить.
- Обучение cGAN исправлению искаженных изображений лиц (например, отсутствие глаза или части носа), особенно между личностями, оказалось сложной задачей. В этом нет ничего неожиданного, поскольку при этом выделяются следующие проблемы:
- Необходимо найти способ изучить структурированные функции на уровне экземпляра образа. Например, восстановление глаза на конкретном изображении, вероятно, не может быть достигнуто путем применения среднего глаза из всех обучающих выборок.
- Необходимо найти способ управлять отношениями на уровне функций в разных моделях.Например, глаз из модели лица Джоли имеет некоторые черты глаза из модели другого человека, но в то же время они не подлежат обмену.
- Необходимо найти способ изучить структурированные функции на уровне экземпляра образа.

 Например, восстановление глаза на конкретном изображении, вероятно, не может быть достигнуто путем применения среднего глаза из всех обучающих выборок.
Например, восстановление глаза на конкретном изображении, вероятно, не может быть достигнуто путем применения среднего глаза из всех обучающих выборок.Описанные выше эксперименты проводились с очень ограниченным количеством выборок данных, а также с ограниченным временем обучения модели. Сделанные выше наблюдения и предложения носят предварительный характер и требуют дальнейшего изучения.
Двигаясь вперед
Есть несколько возможных приложений технологии cGAN (или ее расширения), которые мы хотим изучить в отдельных статьях:
- Используйте cGAN для достижения монокулярного восприятия глубины.
Здесь мы пытаемся выяснить, можно ли использовать cGAN для преобразования обычной фотографии в карту глубины, где оттенки серого в каждом пикселе представляют расстояние до цели (см. Рисунок 7). Мы хотим знать, можно ли обучить cGAN достижению этого, или он просто научится рисовать как подобие карты глубины, которую нельзя обобщить за пределами обучающих выборок. - Используйте cGAN для сегментации изображений.
Здесь мы пытаемся выяснить, можно ли научить cGAN сегментировать и извлекать часть изображения, изучая примеры. - Используйте cGAN для однократного обучения.
Здесь мы стремимся заставить cGAN изучить концепцию только на одном примере обучения с учителем. Например, после того как cGAN обработал несколько изображений лиц без присмотра, добавление метки «нос» к части одного образца позволит ему правильно указывать на носы во всех образцах.
 Рисунок 7). Мы хотим знать, можно ли обучить cGAN достижению этого, или он просто научится рисовать как подобие карты глубины, которую нельзя обобщить за пределами обучающих выборок.
Рисунок 7). Мы хотим знать, можно ли обучить cGAN достижению этого, или он просто научится рисовать как подобие карты глубины, которую нельзя обобщить за пределами обучающих выборок.Благодарности
Я хочу выразить свою признательность команде pix2pix за их отличный документ и реализацию.Без этого эту работу было бы намного труднее завершить.
Я также хочу выразить свою благодарность Фончину Чену и Мишель Чен за предложение сделать наброски от руки, а также за помощь в нескончаемом процессе сбора и обработки изображений, необходимых для проекта.
Что такое, типы и примеры
Что такое функциональная зависимость?
Функциональная зависимость (FD) — это ограничение, которое определяет отношение одного атрибута к другому атрибуту в системе управления базами данных (СУБД).Функциональная зависимость помогает поддерживать качество данных в базе данных. Очень важно найти разницу между хорошим и плохим дизайном базы данных.
Функциональная зависимость обозначена стрелкой «→». Функциональная зависимость X от Y представлена как X → Y. Давайте разберемся с функциональной зависимостью в СУБД на примере.
Пример:
| Номер сотрудника | Имя сотрудника | Заработная плата | Город |
| 1 | 905 905Фрэнсис | 38000 | Лондон |
| 3 | Эндрю | 25000 | Токио |
В этом примере, если мы знаем значение номера сотрудника, мы можем получить имя сотрудника, город, зарплату, и Т. Д.Таким образом, мы можем сказать, что город, имя сотрудника и зарплата функционально зависят от номера сотрудника.
Д.Таким образом, мы можем сказать, что город, имя сотрудника и зарплата функционально зависят от номера сотрудника.
В этом руководстве вы узнаете:
Ключевые термины
Вот несколько ключевых терминов для функциональной зависимости в базе данных:
| Ключевые термины | Описание |
| Axiom Аксиомы — это набор правил вывода, используемых для вывода всех функциональных зависимостей от реляционной базы данных. | |
| Декомпозиция | Это правило предполагает, что если у вас есть таблица, которая, по-видимому, содержит две сущности, которые определяются одним и тем же первичным ключом, вам следует рассмотреть возможность разделения их на две разные таблицы. |
| Зависимый | Отображается справа диаграммы функциональных зависимостей. |
| Определитель | Он отображается в левой части диаграммы функциональных зависимостей.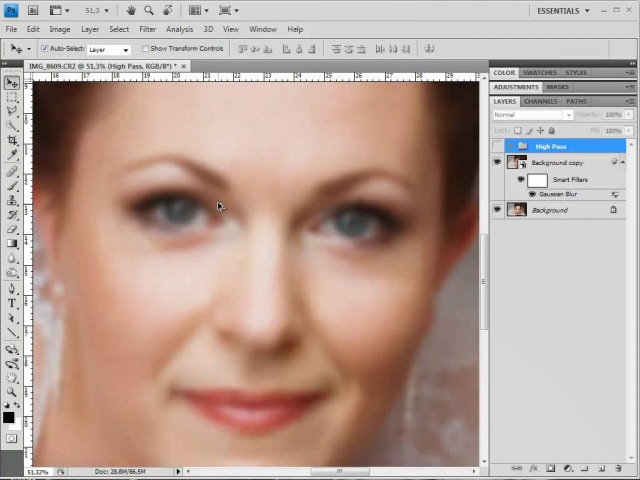 |
| Union | Он предполагает, что если две таблицы разделены, а PK один и тот же, вам следует рассмотреть возможность их размещения. вместе |
Правила функциональных зависимостей
Ниже приведены три наиболее важных правила для функциональной зависимости в базе данных:
- Рефлексивное правило -. Если X является набором атрибутов, а Y является_подмножеством X, то X содержит значение Y.
- Правило увеличения: если выполняется x -> y, а c — установлен атрибут, тогда ac -> bc также выполняется.То есть добавление атрибутов, которые не изменяют основные зависимости.
- Правило транзитивности: это правило очень похоже на правило транзитивности в алгебре, если выполняется x -> y и выполняется y -> z, то x -> z также выполняется. X -> y вызывается как функционально, определяющее y.
Типы функциональных зависимостей в СУБД
В СУБД существует в основном четыре типа функциональных зависимостей. Ниже приведены типы функциональных зависимостей в СУБД:
Ниже приведены типы функциональных зависимостей в СУБД:
- Многозначная зависимость
- Простая функциональная зависимость
- Нетривиальная функциональная зависимость Многозначная зависимость в СУБД
- Функциональная зависимость позволяет избежать избыточности данных. Следовательно, одни и те же данные не повторяются в нескольких местах в этой базе данных
- Это помогает поддерживать качество данных в базе данных
- Это помогает вам определять значения и ограничения баз данных
- Это помогает вам определять плохие конструкции
- помогает найти факты, касающиеся структуры базы данных.
- Функциональная зависимость — это когда один атрибут определяет другой атрибут в системе СУБД.
- Аксиома, Декомпозиция, Зависимость, Детерминантность, Объединение — ключевые термины для функциональной зависимости
- Четыре типа функциональной зависимости: 1) Многозначная 2) Тривиальная 3) Нетривиальная 4) Транзитивная
- Многозначная зависимость возникает в ситуации, когда есть несколько независимых многозначных атрибутов в одной таблице
- Тривиальная зависимость возникает, когда набор атрибутов, который называется тривиальным, если набор атрибутов включен в этот атрибут
- Нетривиальная зависимость возникает, когда A-> B выполняется, где B не является подмножество A
- Транзитив — это тип функциональной зависимости, которая возникает, когда она косвенно формируется двумя функциональными зависимостями
- Нормализация — это метод организации данных в базе данных, который помогает избежать избыточности данных
- Можно ли есть хурму при грудном вскармливании: польза, вред и правила употребления
- Поза для сна новорожденного: рекомендации Комаровского и педиатров
- Во сколько месяцев можно сажать ребенка в ходунки: рекомендации и противопоказания
- Как помочь грудничку избавиться от газиков: эффективные способы и советы
- 2 возникает в ситуации, когда в одной таблице содержится несколько независимых многозначных атрибутов.Многозначная зависимость — это полное ограничение между двумя наборами атрибутов в отношении. Это требует, чтобы в отношении присутствовали определенные кортежи. Для понимания рассмотрим следующий пример многозначной зависимости.
Пример:
| Car_model | Maf_year | Цвет | |||||||||||||||||||||||||||
| H001 | 2017 | 905 905 905 905 905 905 905 905 905 905 Металлик | 2018 | Металлик | |||||||||||||||||||||||||
| H005 | 2018 | Синий | |||||||||||||||||||||||||||
| H010 | 2015 | Металлик | |||||||||||||||||||||||||||
H033 2012 905 905 905 905 905 905 905 независимы друг от друга, но зависят от car_model. В этом примере говорится, что эти два столбца многозначны и зависят от car_model. В этом примере говорится, что эти два столбца многозначны и зависят от car_model.Эта зависимость может быть представлена следующим образом: car_model -> maf_year car_model-> color Trivial Functional Dependency в СУБДTrivial dependency — это набор атрибутов, которые называются тривиальными, если набор атрибутов включен в этот атрибут. Итак, X -> Y — тривиальная функциональная зависимость, если Y является подмножеством X.Давайте разберемся с тривиальным примером функциональной зависимости. Например:
Пример: (Компания} -> {CEO} (если мы знаем компанию, мы знаем имя генерального директора) Но генеральный директор не является частью компании и, следовательно, не является тривиальная функциональная зависимость. Транзитивная зависимость в СУБДТранзитивная зависимость — это тип функциональной зависимости, которая возникает, когда t косвенно формируется двумя функциональными зависимостями. Давайте разберемся со следующим примером транзитивной зависимости. Пример:
{Компания} -> {CEO} (если мы знаем компанию, мы знаем имя ее генерального директора) {CEO} -> {Age} Если мы знаем генерального директора, мы знаем возраст Следовательно, согласно правилу правила транзитивной зависимости: {Компания} -> {Возраст} должно сохраняться, это имеет смысл, потому что, если мы знаем название компании, мы можем узнать его возраст. Примечание. Следует помнить, что транзитивная зависимость может возникать только в отношении трех или более атрибутов. Что такое нормализация?Нормализация — это метод организации данных в базе данных, который помогает избежать избыточности данных, аномалий вставки, обновления и удаления. Это процесс анализа схем отношений на основе их различных функциональных зависимостей и первичного ключа. Нормализация является неотъемлемой частью теории реляционных баз данных.Это может привести к дублированию одних и тех же данных в базе данных, что может привести к созданию дополнительных таблиц. Преимущества функциональной зависимостиРезюме Опубликовано в Разное Больше в РазноеБольше записей в Разное » |
 В отношении, если атрибут B не является подмножеством атрибута A , то это считается нетривиальной зависимостью.
В отношении, если атрибут B не является подмножеством атрибута A , то это считается нетривиальной зависимостью.

Станьте первым комментатором