
Как искусственный интеллект меняет фотографию
Если вас заботит вопрос о том, насколько будет хороша камера вашего следующего смартфона, то стоит обратить внимание на то, что производитель говорит о наличии искусственного интеллекта (ИИ). Если отбросить шумиху и чистый маркетинг, то нет смысла отрицать, что эта технология подняла прогресс фотографии на новый уровень за последние несколько лет и нет никаких сомнений полагать, что темп прогресса замедлятся.
Аппаратное обеспечение тоже не стоит на месте, но самые впечатляющие достижения в области фотографии за последнее время случились на программном уровне, и это во многом благодаря ИИ, который даёт понять объективам куда их навёл пользователь.
Сервис Google Фото продемонстрировал, как искусственный интеллект умеет взаимодействовать с огромными массивами снимков. До его запуска Google использовала машинное обучение для категоризации изображений в Google+, эти навыки перекочевали в Google Фото. ИИ привел в порядок миллиарды неорганизованных пользовательских библиотек в порядок.

Искусственный интеллект Google Фото основывался на предыдущей разработки компании DNNresearch, которую поисковый гигант приобрел в 2013 году. Компания создала нейронную сеть с контролируемым обучением, она могла находить визуальные подсказки на уровне пикселей, чтобы идентифицировать категорию. Со временем алгоритм научился правильно распознавать изображения с помощью шаблонов, например, по снимку панды он обучился правильно идентифицировать другие фотографии панд. Он определяет, где черный мех, а где белый, а также пропорции животного. Используя эту информацию ИИ отличает панд от коров голштинской породы. Все эти «знания» классифицируются и заносятся в базу данных, они используются для поиска снимков по абстрактным терминам, таким, как «животное» или «завтрак».
Подобный алгоритм требует много времени и вычислительной мощности, поэтому вся работа выполняется на серверах компании после того, как снимок загружается в облако. Как только фотографии попадают в центр обработки данных (ЦОД) Google начинает использование алгоритма для анализа и маркировки. Примерно через год после запуска сервиса Google Фото компания Apple анонсировала функцию поиска фотографий, которая аналогичным образом задействовала нейронные сети, но в рамках обязательств компании по обеспечению конфиденциальности категоризация выполняется процессором устройства без отправки данных на сервера. Обычно этот процесс занимает несколько дней и происходит в фоновом режиме.

Искусственный интеллект и машинное обучение, помимо управления фотографиями, также оказывают большое влияние на процесс создания снимка. Количество объективов на спинках смартфонов растет как грибы, а матрицы увеличиваются в размерах, но физику не обманешь — прогресс ограничивает толщина корпуса мобильных устройств. Несмотря на это, современные смартфоны нередко делают более качественные снимки, чем некоторые камеры. Всё потому, что обычные камеры не в состоянии конкурировать с аппаратным обеспечением смартфонов, которое также важно для фотографии — центральный процессор (ЦП), процессор обработки сигналов изображения и блок ИИ, если такой предусмотрен производителем.

Google остается очевидным лидером в области «вычислительной фотографии» и превосходные результаты камер всех трех поколений Pixel тому доказательство. Режим HDR+ использует сложный алгоритм, объединяющий несколько снимков с разным уровнем экспозиции в одну фотографию. Наличие машинного обучения означает, что система продолжает улучшаться со временем. Google обучил свой искусственный интеллект огромному набору данных с помощью сервиса Google Фото и эти знания помогают камере Pixel в подборе правильной экспозиции.
Говоря о преимуществе смартфонов Google стоит упомянуть режим Night Sight, который с помощью длинных выдержек и алгоритма машинного обучения показывает впечатляющие результаты на съемках в условиях плохого освещения. Эта функция наилучшим образом реализована в Pixel 3, потому что алгоритмы разрабатывались с учетом аппаратного обеспечения этого устройства. Несмотря на это, Google сделала режим Night Sight доступным для всего модельного ряда смартфонов Pixel, даже для самых первых, в которых отсутствует оптическая стабилизация. Это решение доказывает, что программное обеспечение выходит на первый план, когда дело доходит до мобильной фотографии.

Тем не менее, аппаратная составляющая все еще имеет значение, особенно в случаях, когда она умеет взаимодействовать с искусственным интеллектом. Отдельные процессоры обработки изображения были очень важны для качества мобильной фотографии, но похоже, что чипы с ИИ будут играть более важную роль в развитии цифровой фотографии. Huawei была первой компанией, представившей систему на кристалле (SoC) с искусственным интеллектом — Kirin 970, хотя Apple Bionic A11 в конечном итоге первым добрался до пользователей. Крупнейший поставщик процессоров Qualcomm не уделяет особого внимания машинному обучению. Google разработала свой собственный чип под названием Pixel Visual Core, который помогает решать задачи связанные с ИИ. Последняя версия Apple A12 Bionic оснащена восьмиядерным нейронным движком, который может выполнять задачи в среде машинного обучения Apple до 9 раз быстрее, чем A11. Apple сообщает, что это дает камере лучшее понимание фокальной плоскости, а это помогает создавать более реалистичную глубину резкости.
Эта технология важнее для эффективного и производительного машинного обучения прямо на устройстве. Google продемонстрировала впечатляющую работу, которая снижает нагрузку на обработку с ghvhom. ЦОД, в то же время нейронные движки (Neural Engine) становятся быстрее с каждым годом. На раннем этапе развития «вычислительной» фотографии у камер смартфонов, которые разрабатывались для работы в тандеме с машинным обучением, есть реальные преимущества. Из всех возможностей искусственного интеллекта, фотография — наиболее практичная область применения. Камера — неотъемлемая часть любого смартфона, а ИИ — отличный способ её улучшить.
iGuides в Telegram — t.me/igmedia
iGuides в Яндекс.Дзен — zen.yandex.ru/iguides.ru
www.iguides.ru
Искусственный интеллект улучшает фото со смартфонов

Хотите улучшить фотографии со смартфона до уровня зеркальных камер? Исследовательская группа ученых ETH Zurich из Швейцарии пытается сделать это возможным. Они создали нейронную сеть, которая направлена на автоматическое повышения низкого качества снимков с телефонов.
«Компактные мобильные камеры имеют не высокое качество снимков в основном за счет маленького размера и ограничений стоимости устройств», пишут ученые. «Мы предлагаем решение проблемы на основе обучения искусственного интеллекта, который преобразует фотографии, сделанные с помощью компактных камер до уровня профессиональных фотоаппаратов».
Сначала ученые обучили систему, показывая ей качественные фотографии с зеркальных камер. Затем были показаны сниммки, сделанные в тех же местах на смартфоны iPhone 3Gs, BlackBerry Passport и Sony Xperia Z. Также использовалась камера Canon 70D. После было использовано множество снимков с различных зеркальных камер. Которые уже не были связаны с аналогичными фотографиями со смартфонов.
Таким образом, вместо того, чтобы использовать гигантский массив данных качественных фото в паре со снимками со смартфонов, учёным удалось создать базу данных только из хороших фотографий.
Вот примеры до и после применения алгоритма улучшения:

 После iPhone 6.
После iPhone 6. До. Nexus-5X
До. Nexus-5X После. Nexus-5X
После. Nexus-5X До. HTC-One-M9
До. HTC-One-M9 После. HTC-One-M9
После. HTC-One-M9
 После. Xiaomi-Redmi-3X
После. Xiaomi-Redmi-3X До. HTC-One-M9
До. HTC-One-M9 После. HTC-One-M9
После. HTC-One-M9 До
До После
ПослеКак вы можете видеть из этих примеров фотографий, у нейронной сети есть плохая привычка пересвечивать небо, теряя детализацию. Алгоритм всё ещё находится в стадии обучения и наверняка данный недочёт будет исправлен.
Ученые из ETH Zurich говорят, что преимущество их системы заключается в возможности обучать себя для работы с любой новой камерой при помощи набора фотографий.
Хотите попробовать эту нейронную сеть? Ученые создали веб-страницу, которая позволяет загружать собственные фотографии, сделанные на смартфон и получать улучшенный вариант.
Следите за новостями: Facebook, Вконтакте и Telegram
comments powered by HyperCommentsphotar.ru
ИИ научился создавать видео с одного кадра. Старые картины теперь можно сделать живыми
Технология из Гарри Поттера дошла до наших дней. Теперь для создания полноценного видео человека достаточно одной его картинки или фотографии. Исследователи машинного обучения из «Сколково» и центра Samsung AI из Москвы опубликовали свою работу о создании такой системы, вместе с целым рядом видео знаменитостей и предметов искусства, получивших новую жизнь.
Текст научной работы можно почитать тут. Там всё довольно интересно, с массой формул, но смысл прост: их система руководствуется «ориентирами», достопримечательностями лица, вроде носа, двух глаз, двух бровей, линии подбородка. Так она мгновенно улавливает, что человек собой представляет. И потом может переносить всё остальное (цвет, текстуру лица, усы, щетину и прочее) на любое другое видео человека. Адаптируя старое лицо к новым ситуациям.
Разумеется, это пока работает только на портретах. Модели нужен только один человек, с лицом, повернутым к нам, чтобы у него было хотя бы видно оба глаза. Тогда система может делать с ним что угодно, передавать ему любую мимику. Достаточно дать ей подходящее видео (с другим человеком с головой примерно в том же положении).
Ранее ИИ уже научился делать дипфейки, и интернет-пользователи знатно поиздевались над знаменитостями, вставляя их лица в порно и делая мемы с Николасом Кейджем. Но для этого им приходилось тренировать алгоритмы мегабайтами (а лучше – гигабайтами) данных, находить как можно больше изображений и видео с лицами знаменитостей, чтобы выдать более-менее пристойный результат. Сам создатель Deepfakes говорил, что на компиляцию одного короткого ролика у него уходит 8-12 часов. Новая система генерирует результат моментально, а на входе ей достаточно одной картинки.
С предыдущей системой мы никогда бы не смогли посмотреть на живую Мону Лизу, у нас есть только один её ракурс. Теперь, с алгоритмами, работающими по ориентирам, это становится возможным. Идеала не достичь, но уже что-то близко.
В работе московских исследователей также используется генеративно-состязательная сеть. Две модели алгоритма сражаются друг с другом. Каждая пытается обмануть оппонента, и доказать ему, что то видео, которое она создает – настоящее. Так достигается определенный уровень реализма: картинка человеческого лица не выпускается «в свет», если модель-критик не уверена в её подлинности более чем на 90%. Как говорят авторы в своей работе, в изображениях регулируются десятки миллионов параметров, но за счет такой системы, работа кипит очень быстро.
Если картинок несколько, результат улучшается. Опять же, проще всего получается работать со знаменитостями, которые уже сняты со всех возможных ракурсов. Для достижения «идеального реализма» нужны 32 снимка. В этом случае сгенерированные ИИ фото в невысоком разрешении будут неотличимы от настоящих фото человека. Нетренированные люди на этом этапе уже не способны выявить фейк – возможно, шансы остаются у экспертов или у близких родственников «подопытного» со всех этих изображений.
Если фото или картинка только одна, итог пока не всегда самый лучший. Увидеть артефакты на видео, когда голова находится в движении, можно без особых проблем. Сами исследователи говорят, что их самое слабое место – взгляд. Модель, основанная на ориентирах лица, пока не всегда понимает, как и куда человек должен смотреть.
habr.com
никто из этих людей не существует
Способность нейронных сетей создавать фотореалистичные изображения настолько продвинулась, что едва ли кто-нибудь усомнится в подлинности этих портретов. Хотя они полностью сгенерированы искусственным интеллектом. То есть ни одного из этих людей не существует.
Как сообщает PetaPixel, исследователи компании NVIDIA опубликовали статью о возможности получения реалистичных лиц, созданных генеративно-состязательной сетью (Generative adversarial network, сокращённо GAN).
The Verge отмечает, что GAN существует всего около четырёх лет. Саму концепцию представили в статье, опубликованной в 2014 году. Так выглядели результаты, полученные ИИ в то время:

Менее чем за полдесятилетия реализм изображений улучшился до такой степени, что большинство людей не заподозрят, что эти портреты поддельные. Даже при ближайшем рассмотрении.
Исследователи NVIDIA теперь могут копировать черты лиц с подлинных портретов, смешивать их и создавать изображения, выглядящие как совершенно новые люди:

Чтобы создать эти лица, специалисты NVIDIA обучали ИИ в течение недели, используя 8 мощных графических процессоров. Ниже 6-минутное видео об их прогрессе:
Коллаж из лиц, сгенерированных ИИ:

Технология не ограничивается созданием лиц. Она способна генерировать различные изображения – от ненастоящих фотографий интерьеров до поддельных снимков автомобилей или кошек:



Искусственно сгенерированные изображения находят применение не первый год. Ещё в 2014-ом 75% фотографий каталога ИКЕА были созданы компьютером. В будущем создание нужных «фотографий из воздуха», похоже, станет ещё более широко распространённой практикой.
Смотрите также:
cameralabs.org
12 полезных AI-сервисов, на которые стоит обратить внимание
О том, что технологии искусственного интеллекта сегодня являются темой номер один в IT-индустрии, можно судить не только по восторженным публикациям в СМИ и многочисленным проектам в этой сфере, но и по масштабам проникновения AI практически по все области современной жизни — от медицины, экспертных систем и научных исследований до промышленной робототехники и автопилотируемого транспорта. Направление машинного обучения и нейронных сетей активно развивается и совершенствуется, в нём задействованы Intel, AMD, NVIDIA, IBM, Google, Facebook, «Яндекс», ABBYY, а также тысячи других компаний-разработчиков по всему миру. Не скрывают своего интереса к искусственному интеллекту и различные инвестиционные фонды. Всё это заставляет с оптимизмом смотреть на будущее рынка умных AI-решений, которому аналитики прочат почти 30-кратный рост в ближайшее десятилетие. Впечатляющий показатель! Неудивительно, что сегодняшний обзор мы посвятили именно продуктам, использующим «электронный разум».

Remove.bg. Бесплатный AI-сервис, позволяющий за считаные секунды удалить фон на фотографиях без использования графических редакторов. Достаточно загрузить изображение — и система автоматически, с использованием алгоритмов искусственного интеллекта выделит объекты на переднем плане и уберёт всё лишнее. По заверениям разработчиков, лучше всего Remove.bg справляется со снимками людей, что, впрочем, не мешает использовать сервис для обработки фото с различными предметами — иногда результат получается очень даже неплохим. К загрузке принимаются картинки любого размера, однако итоговый вариант изображения (файл формата PNG с прозрачным фоном) ограничен разрешением 500 на 500 пикселей.

«Яндекс.Алиса». Голосовой помощник, который вряд ли нужно представлять широкой публике и который в полной мере демонстрирует возможности современных технологий машинного обучения и систем искусственного интеллекта на базе нейронных сетей. По набору функций «Алиса» действительно способна дать фору многим другим AI-проектам: она отлично владеет русским языком, умеет давать быстрые ответы на вопросы и прокладывать маршруты, рассказывать сказки детям, вызывать такси, совершать покупки в интернет-магазинах, играть в различные игры, разбираться в музыке, распознавать фотографии, а также выполнять прочие действия. Отличительными особенностями «Алисы» являются умение общаться на отвлечённые темы и возможность встраивания голосового помощника в различные сервисы.

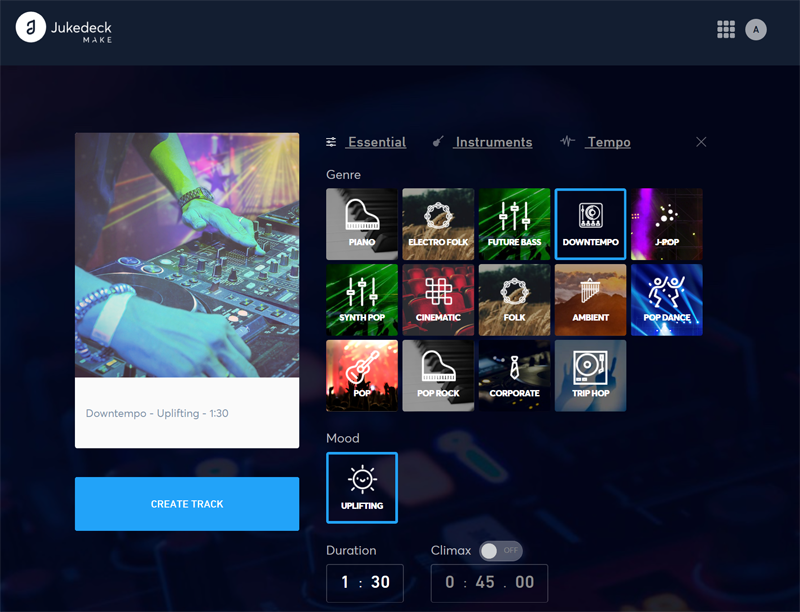
Jukedeck. Сервис, использующий всю мощь AI-технологий для создания музыкальных треков различных жанров. Всё, что требуется от пользователя, — это определить начальные параметры будущей композиции (жанр, темп, настроение, длительность, состав инструментов), после чего щёлкнуть по клавише Create Track и дождаться завершения обработки запроса. Сочинённую искусственным интеллектом музыку можно прослушать в браузере, скачать на компьютер либо отправить на доработку, откорректировав характеристики трека. Примечательно, что созданные Jukedeck произведения не требуют авторских отчислений и их можно использовать по своему усмотрению — например, для звукового сопровождения видеороликов на YouTube, публикации в социальных сетях, пополнения фонотеки или музыкального творчества.
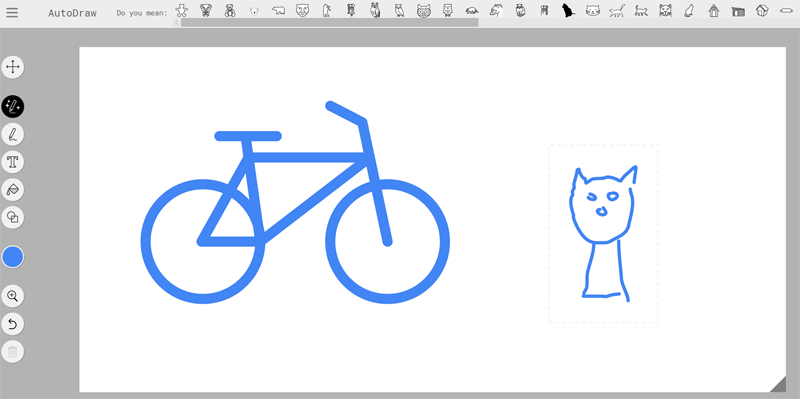
Google AutoDraw. Сервис, превращающий рисунки от руки в высококачественные клип-арты. Положенный в основу AutoDraw искусственный интеллект в реальном времени анализирует пользовательские наброски, распознаёт их и предлагает аналогичные картинки, нарисованные профессиональными художниками. Созданные иллюстрации можно разместить в социальных сетях либо скачать на компьютер для дальнейшего использования. Важно отметить, что разработанный компанией Google сервис прекрасно подходит не только для развлечения, но и для решения вполне реальных задач. Например, добрую службу AutoDraw может сослужить дизайнерам-оформителям презентаций, иллюстраторам, фоторедакторам и представителям прочих творческих профессий.
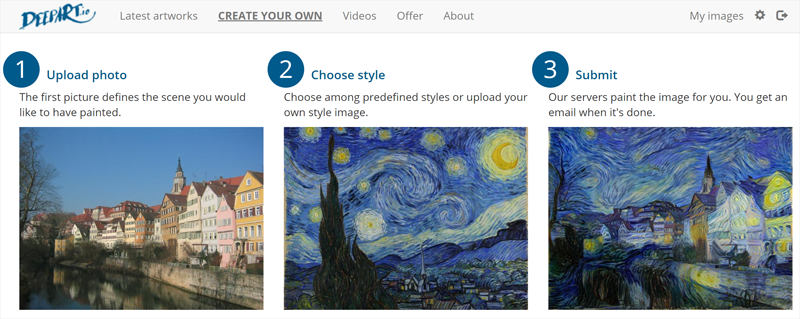
Deepart.io. Ещё один AI-сервис, предназначенный для работы с графикой и создания оригинальных картин на основе пользовательских изображений. Техника работы с Deepart.io предельно простая: загружаем на сервер сервиса фотографию, указываем предпочтительный художественный стиль и дожидаемся завершения процесса отрисовки картины, который может занять продолжительное время. Для тех, кто не желает ждать, разработчики сервиса предлагают несколько вариантов платных подписок, позволяющих не только свести к минимуму время рендеринга шедевров цифрового искусства, но и снять ограничения на размер выходных изображений.
Beautiful.ai. Онлайновый инструмент для создания презентаций, использующий технологии искусственного интеллекта с целью автоматизации и упрощения работы пользователя со слайдами. «Умные» алгоритмы сервиса контролируют каждый шаг при работе с презентацией и делают так, чтобы просмотр слайдов был более комфортным. Beautiful.ai анализирует расположение элементов презентации и автоматически перестраивает слайды, корректирует их цветовое оформление, перерисовывает графики, подбирает анимационные переходы, рекомендует подходящие по тематике контента шаблоны и выполняет прочие действия, стараясь, чтобы подача материала на слайдах была профессиональной с точки зрения дизайна. Beautiful.ai имеет собственную библиотеку шаблонов и изображений, поддерживает совместную работу над документами, позволяет сохранять созданные презентации в облачном хранилище и экспортировать их в файлы форматов PDF и PowerPoint. В общем, рекомендуем.

Let’s Enhance. Сервис, который позволяет улучшать фотографии и масштабировать их без потери качества. «Сердцем» данного программного решения является обученная на большой базе снимков нейронная сеть, которая благодаря знаниям типичных объектов и текстур умеет восстанавливать детали и сохранять чёткие линии и контуры обрабатываемых изображений. Let’s Enhance может не только увеличивать разрешение фотографии в четыре раза, но и удалять шумы и артефакты сжатия на снимках формата JPEG, а также дорисовывать недостающие мелкие детали, делая картинку, как заверяют разработчики, максимально реалистичной. Для рядовых пользователей в системе установлено ограничение в 15 мегапикселей и 15 мегабайт для каждого загружаемого файла. Оформившим платную подписку на услуги сервиса предлагается максимальный приоритет в обработке изображений и возможность загружать картинки с разрешением до 30 мегапикселей.

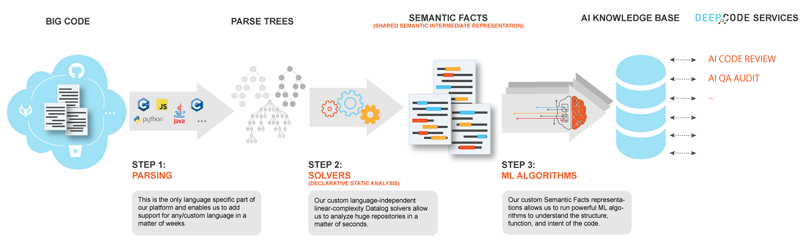
DeepCode. Сканер программного кода, «электронный разум» которого умеет находить ошибки и предоставлять разработчикам рекомендации по их исправлению. В основу сервиса положены знания более чем четверти миллиона алгоритмических правил, принципов и методов разработки ПО, оперируя которыми искусственный интеллект системы может проверять и оценивать качество кода. DeepCode поддерживает работу с JavaScript, Java, Python и широко востребованным в профессиональной среде репозиторием GitHub.
Yva. Облачная система «умной» аналитики корпоративных коммуникаций, позволяющая с помощью технологий искусственного интеллекта оценивать эффективность работы персонала компании. Yva подключается к корпоративной почте, мессенджерам, проводит регулярные опросы сотрудников и анализирует полученные данные. В результате система формирует рекомендации и предупреждения каждому сотруднику и руководителю, позволяя контролировать их работу, предотвращать «выгорание» и увольнение ключевых работников и другие возможные риски. Система также позволяет на ранних этапах предотвращать конфликты в коллективе и узнавать компетенции каждого сотрудника, будь то его сильные и слабые стороны, лидерские качества, вовлечённость в работу и прочие характеристики. Сильной стороной Yva является независимость от предметной области и умение автоматически адаптироваться к коммуникационной среде организаций самых разных отраслей и любого размера. Более подробно о том, как работает эта система, можно узнать в нашем обзоре продукта.
Colorize. Сервис, использующий технологии искусственного интеллекта для раскрашивания чёрно-белых фотографий. Работа с Colorize реализована по принципу «проще не бывает»: загружаем снимок или указываем ссылку на изображение в глобальной сети — и на выходе, спустя несколько минут, получаем цветное фото. Справедливости ради стоит отметить, что с раскрашиванием изображений AI-движок сервиса справляется не всегда идеально, но иногда результаты получаются действительно впечатляющими.
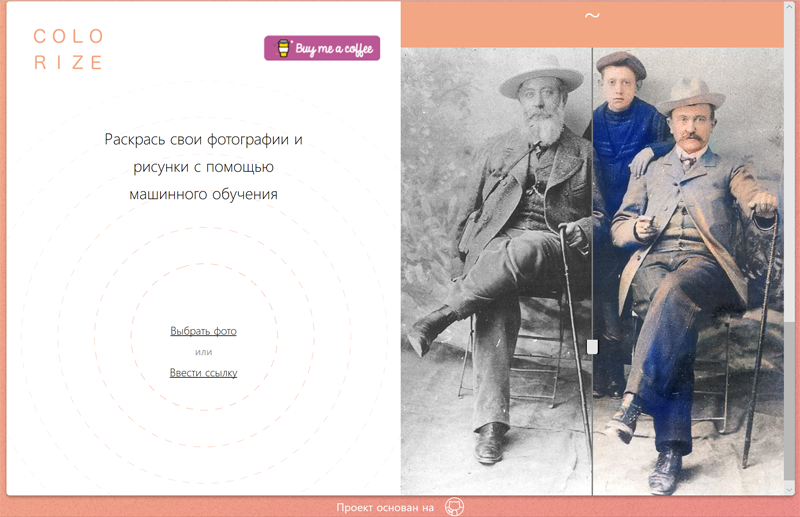
CaptionBot. Онлайновый сервис компании Microsoft, который распознает объекты на загружаемых пользователем изображениях и с помощью нейронных сетей описывает то, что находится на фото, причём простыми человеческими словами. Особенностью CaptionBot является использование сразу двух систем искусственного интеллекта — Computer Vision (компьютерное зрение) и Natural Language Processing (анализ и синтез естественных языков). И этот тандем действительно работает!
Ну а завершает наш обзор разработанный компанией Mail.Ru Group сервис аудиоаналитики Sounds. Положенные в его основу AI-технологии позволяют распознавать голоса, отдельные звуки и их комбинации в аудиопотоке, различать громкость, тональность и интенсивность звучания, выполнять преобразование речи в текст и решать прочие задачи. Благодаря широким функциональным возможностям Sounds может использоваться во множестве сценариев. К примеру, сервис может найти применение для распознавания выстрелов и драк на улицах и последующего оповещения полиции, охраны помещений, акустического наблюдения за неисправностями в работе промышленного оборудования, очистки аудиозаписей от шумов, идентификации людей по голосам, оценки тональности речи и её конвертирования в текст, а также для скрытия нецензурной лексики в радио- и телепередачах в прямом эфире. Для интеграции системы в программные продукты предусмотрен соответствующий API.
Есть что добавить? Пишите в форме для комментариев ниже.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
3dnews.ru
Photolemur. Можно ли с помощью искусственного интеллекта обрабатывать фотографии: liseykina — LiveJournal

Нет кнопок — нет проблем” — отличный девиз для программы для обработки фотографий?
Но все так и есть.
Photolemur программа для того чтобы сделать ваши фотографии лучше. Без настроек. Без кнопок. На основе искуственного интеллекта.
Фотографию для обработки можно перетащить в окошко, открыть по правой кнопке мыши ну или нажать на кнопку “Open”.
Потом начинает происходить магия, которая красиво визуализируется

Можно позалипать на нейросеть и почитать комментарии, описывающие что примерно будет происходить с вашей фотографией.
Получается вот так:
 до |  после |
Как-то повлиять на результат можно только отрегулировав степнь воздействия.
Для этого под картинкой находится ползунок

То что получилось можно сразу экспортировать в социальные сети или сохранить на жесткий диск

При экспорте на жесткий диск доступны расширенные настройки — можно поменять размер, качество фотографии, разрешение и сохранить настройки в виде пресетов. Довольно удобно — можно сделать отдельный пресет для
экспорта полноразмерных изображений и для web-версий.

Все нужные форматы на месте. Tiff можно сохранить либо в 16bit, либо в 8.

Не обязательно “обрабатывать” по одной фотографии — можно открыть сразу всю папку с фотографиями из отпуска, запустить искусственный интеллект, уйти спать, а по возвращении обнаружить обработанные фотографии в отдельной папке — удобно, если хочется легко, быстро и не задумываясь привести снимки к “смотрибельному” виду.

Можно сделать экспорт либо одной фотографии, либо всех открытых сразу, либо выбрать несколько с зажатой клавишей Ctrl и экспортнуть только их. Например, это удобно для того чтобы разные фотографии из папки сохранить с разными настройками.
Вот и все. А теперь давайте посмотрим что Photolemur делает с фотографиями.
Корректировки сводятся к выравниванию освещенности, коррекции цветов, контраста, правке искажений оптики.
Я специально старалась подбирать максимально разнообразные примеры, чтобы оценить как программа обработает фотографии снятые при разных настройках и с разным светом.
Вот что получается в сухом остатке:
- Картинки с плоским и не интересным светом, снятые в полдень обрабатывает очень даже — получается контрастно и объемно
- С ночными фотографиями особой разницы нет. Ну не умеет Photolemur работать со звездным небом.
- Ночной город — норм. Стало лучше, чем было
- Сложный контровый свет тоже нормально. Фотография хуже не стало.
- Сумерки и высокие ISO очень не однозначно. Например, фотография с оленями снята на ISO 12800 — Photolemur сделал ее более контрастной и светлой из-за чего появился просто дикий шум, который видно даже на превью. А снимок на аналогичном ISO из Кельна (последний в подборке) только выиграл от обработки. Цвета получились, вообще, отличные.
- Оттенок зеленого, который получается после обработки мне не нравится категорически. Но это вкусовщина.
- Детали в тенях и светах восстанавливает отлично.
Получается, что Photolemur подойдет для быстрой коррекции, когда нет времени или желания обрабатывать фотографии вручную, надо быстро выложить в социальные сети, в статью или еще куда-нибудь. В большинстве случаев
результат обработки лучше чем исходник. Но чтобы обработка вас не разочаровала лучше выбирать исходники не с очень большим ISO и снятые “без экстрима” — дневние, утренние с мягким и рассеянным светом. Потому что при высоких ISO после обработки шум становится более заметным. А вот работа со светом понравилась, даже контровый свет Photolemur отрабатывает хорошо.
Photolemur стоит 35$ и доступен для Windows и MacOS. Скачать тестовую бесплатную верию можно кликнув на баннер
liseykina.livejournal.com
Психоделические рисунки искусственного интеллекта (10 фото) » Триникси
В наше время рисовать могут не только люди, но и машины. Далее вас ждут картины, созданные искусственным интеллектом компании Google, которая недавно решала провести тестирование искусственных нейронных сетей, распознающих и описывающих изображения. Основываясь на определенных запросах человека, система создала серию психоделических рисунков, отражающих видение окружающего нас мира искусственным интеллектом.Красное дерево
В новом докладе под названием «Инсептионизм: углубление в нейронные сети» исследовательская группа Google подробнейшим образом анализирует работу искусственных нейронных сетей, особенно в качестве программного обеспечения, предназначенного для распознавания изображений.
")
Гора МакКовен
Команда исследователей попробовала «научить» сеть, показывая ей примеры изображений, которые она должна была запомнить. Например, чтобы научить ИИ, что означает слово «горы», они показывали ей различные фото гор.
")
Повторяющиеся места
Тем не менее, они получили довольно странные результаты, когда попросили сеть создать собственное изображение на основе того, что она «выучила». В одном случае, когда ей велели нарисовать гантели, сеть создала картинку, где объединила металл и человеческие руки, вероятно, из-за того, что каждый образ с гантелями, который был ей показан, включал в себя руки, держащие гантели.
")
Генерирование изображений
В некоторых иных тестах команда исследователей попросила нейронные сети найти на изображениях конкретные вещи, которых на самом деле там не было. Идея заключалась в том, чтобы заставить искусственный интеллект модифицировать начальное изображение для получения желаемого объекта.
")
Нейронная статическая память
Во ходе других испытаний сотрудники Google сказали сети ИИ производить случайные изображения без подсказок, основываясь лишь на случайных нейронных воспоминаниях, присутствующих в статической памяти.
")
Странный Сиэтл
Исследователи Google говорят о таких случайно генерируемых изображениях, как о «снах» искусственной нейронной сети.
")
Водопад
Оказывается, ИИ может спать и видеть удивительных овец вместе с деформированными птицами и множеством глаз…
")
И может также видеть много других сумасшедших визуальных изображений. Наверно так выглядит «Властелина Колец», если смотреть его под кайфом.
")
Крик
Если считать картины искусственного интеллекта отчасти примером модернистского искусства, то вероятно, весьма приемлемо, что ИИ использовал несколько приемов Эдварда Мунка, с помощью которых тот создавал «Крик». Но при чем здесь настойчивое использование глаз? И неужели это… собака с левой стороны картины?
")
Красивые и сложные
Другие изображения оказались необыкновенно красивыми и сложными одновременно. Команда Google планирует продолжить свое наблюдение за тем, какие образы формируются на глубоких нейронных уровнях, поскольку она решила продолжить обучение искусственного интеллекта, чтобы тот смог лучше распознавать необходимые изображения.
")
Отсюда
trinixy.ru
Станьте первым комментатором